These notes rely on PSU1, STHDA2, and (Molnar 2020),
The population regression model \(E(Y) = X \beta\) summarizes the trend between the predictors and the mean responses. The individual responses are assumed to be normally distributed about the population regression, \(y_i = X_i \beta + \epsilon_i\) with varying mean, but constant variance, \(y_i \sim N(\mu_i, \sigma^2).\) Equivalently, the model presumes a linear relationship between \(y\) and \(X\) with residuals \(\epsilon\) that are independent normal random variables with mean zero and constant variance \(\sigma^2\). Estimate the population regression model coefficients as \(\hat{y} = X \hat{\beta}\), and the population variance as \(\hat{\sigma}^2\). The most common method of estimating the \(\beta\) coefficients and \(\sigma\) is ordinary least squares (OLS). OLS minimizes the sum of squared residuals from a random sample. The predicted values vary about the actual value, \(e_i = y_i - \hat{y}_i\), where \(\hat{y}_i = X_i \hat{\beta}\).
The OLS model is the best linear unbiased estimator (BLUE) if the residuals are independent random variables normally distributed with mean zero and constant variance. Recall these conditions with the LINE pneumonic: Linear, Independent, Normal, and Equal.
Linearity. The explanatory variables are each linearly related to the response variable: \(E(\epsilon | X_j) = 0\).
Independence. The residuals are unrelated to each other. Independence is violated by repeated measurements and temporal regressors.
Normality. The residuals are normally distributed: \(\epsilon|X \sim N(0, \sigma^2I)\).
Equal Variances. The variance of the residuals is constant (homoscedasticity): \(E(\epsilon \epsilon' | X) = \sigma^2I\)
Additionally, there should be little multicollinearity among the explanatory variables.
If the modeling objective is inference, fit the model with the full data set, evaluate the model fit, and interpret the parameter estimates. If the objective is prediction, fit the model with a partitioned train/test data set, cross-validate the fit with the test set, then deploy the model. Both are covered below.
1.1 Parameter Estimation
There are two model parameters to estimate: \(\hat{\beta}\) estimates the coefficient vector \(\beta\), and \(\hat{\sigma}\) estimates the variance of the residuals along the regression line. Derive \(\hat{\beta}\) by minimizing the sum of squared residuals \(SSE = (y - X \hat{\beta})' (y - X \hat{\beta})\). The result is
\[\hat{\beta} = (X'X)^{-1}X'y.\]
The residual standard error (RSE) estimates the sample deviation around the population regression line. (Think of each value of \(X\) along the regression line as a subpopulation with mean \(y_i\) and variance \(\sigma^2\). This variance is assumed to be the same for all \(X\).)
\[\hat{\sigma} = \sqrt{(n-k-1)^{-1} e'e}.\]
The standard error for the coefficient estimators is the square root of the error variance divided by \((X'X)\).
Linear regression is related to correlation. The coefficient estimator for \(\beta_1\) in simple linear regression is equal to the Pearson correlation coefficient multiplied by the ratio of the standard deviations of \(y\) and \(x\).
The formula for \(\hat{\beta}\) is almost identical to that of \(r\) with the exception that the denominator is the variance of \(X\) rather than the product of the standard deviations. The Pearson correlation is the standardized linear relationship. Pearson correlation measures the strength and direction of the linear relationship between \(X\) and \(Y\) in a standardized form.
If \(r = 0\), then \(\beta_1 = 0\) and there is no linear relationship.
if \(r = 1\) or \(r = -1\), then the relationship is perfectly linear, and \(\beta_1\) measures the relative scale of \(Y\) and \(X\).
Example
Dataset mtcars contains response variable fuel consumption mpg and 10 aspects of automobile design and performance for 32 automobiles. What is the relationship between the response and its predictors?
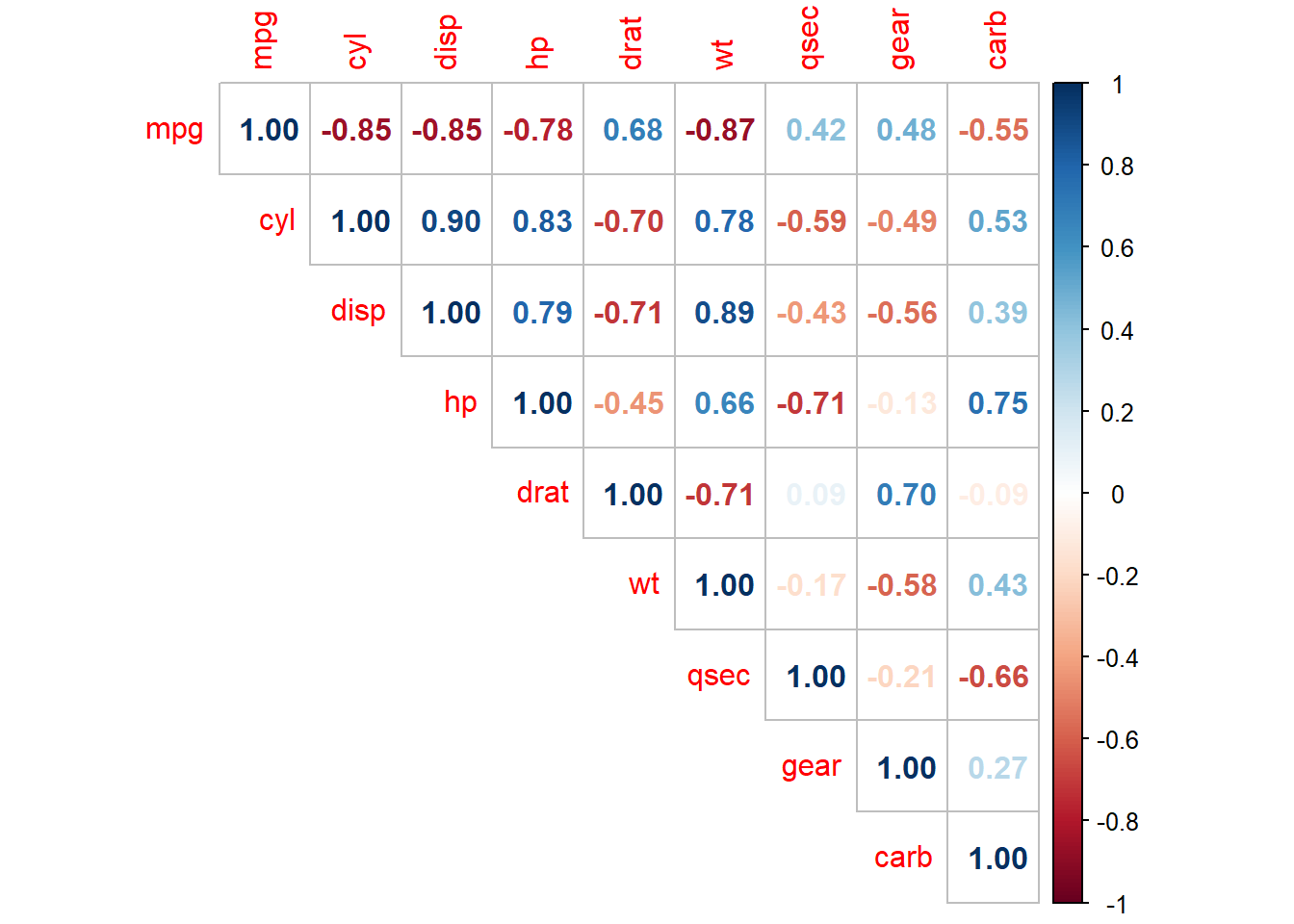
The correlation matrix of the numeric variables shows wt has the strongest association with mpg (r = -0.87) followed by disp (r = -0.85) and hp (r = -0.78). drat is moderately correlated (r = 0.68), and qsec is weakly correlated (r = 0.42). Many predictors are strongly correlated with each other.
summary() shows \(\hat{\beta}\) as Estimate, \(SE({\hat{\beta}})\) as Std. Error, and \(\hat{\sigma}\) as Residual standard error. You can manually perform these calculations using matrix algebra3. Recall, \(\hat{\beta} = (X'X)^{-1}X'y\).
Show the code
X <-model.matrix(fit)y <- mt_cars$mpg(beta_hat <-solve(t(X) %*% X) %*%t(X) %*% y)
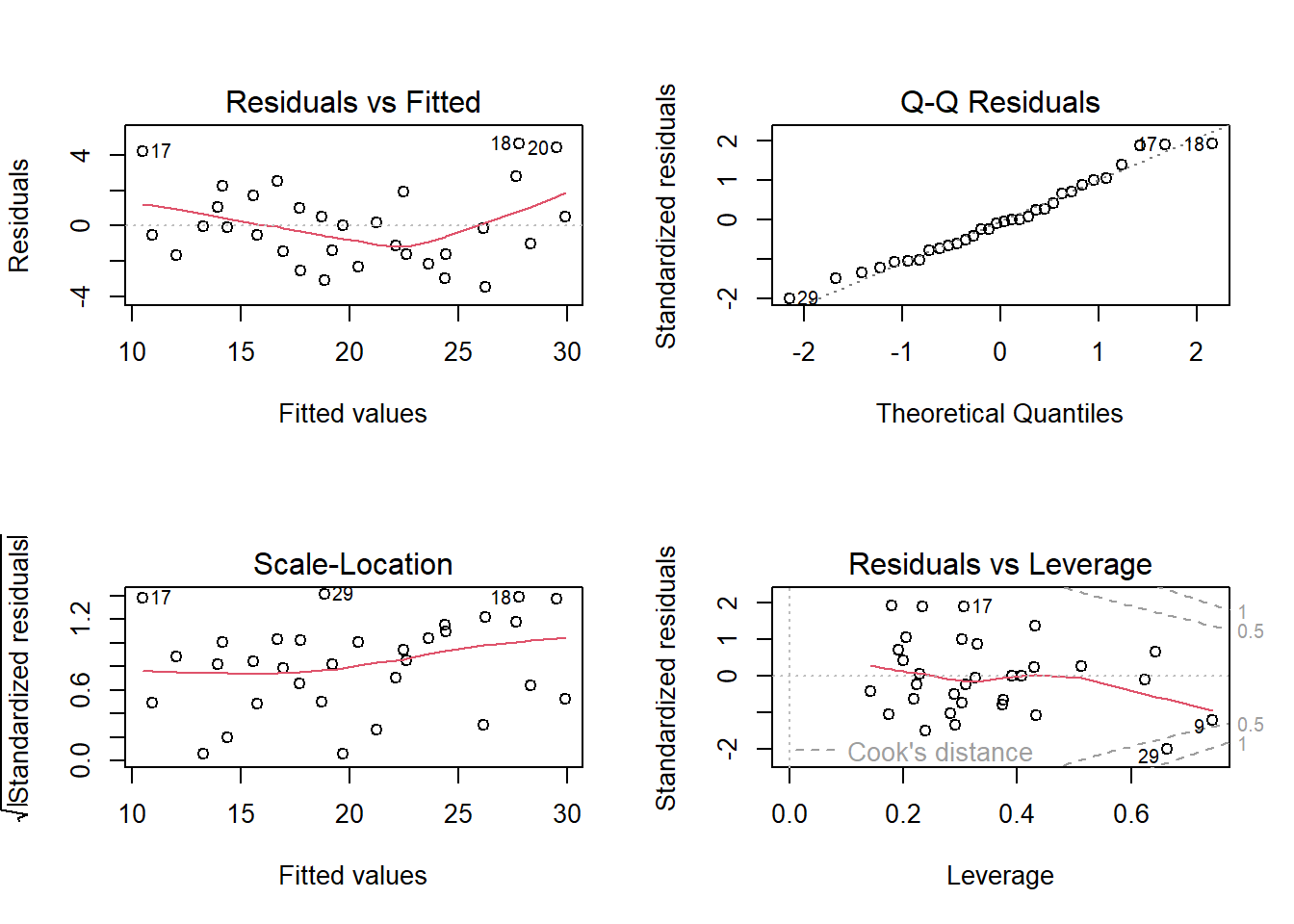
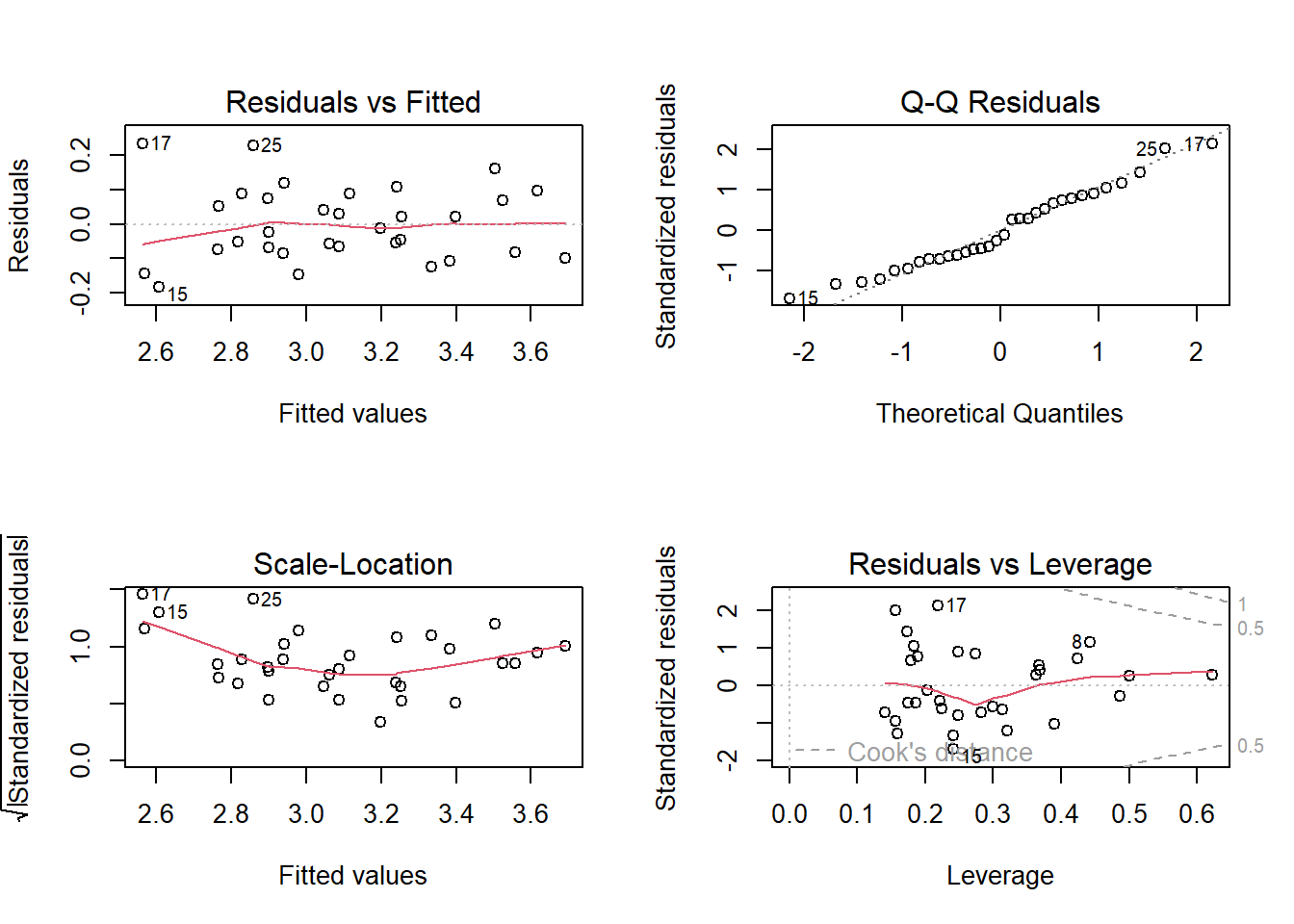
The linear regression model assumes the relationship between the predictors and the response is linear and the residuals are independent random variables normally distributed with mean zero and constant variance. Additionally, you will want to check for multicollinearity in the predictors because it can produce unreliable coefficient estimates and predicted values. The plot() function produces a set of diagnostic plots to test the assumptions.
Use the Residuals vs Fitted plot, \(e \sim \hat{Y}\), to test the linearity and equal error variances assumptions. The plot also identifies outliers. The polynomial trend line should show that the residuals vary around \(e = 0\) in a straight horizontal line (linearity). The residuals should have random scatter in a band of constant width around 0, and no fan shape at the low and high ends (equal variances). All tests and intervals are sensitive to the equal variances condition. The plot also reveals multicollinearity. If the residuals and fitted values are correlated, multicollinearity may be a problem.
Use the Q-Q Residuals plot (aka, residuals normal probability plot) to test the normality assumption. It plots the theoretical percentiles of the normal distribution versus the observed sample percentiles. It should be approximately linear with no bow-shaped deviations. Sometimes this normality check fails when the linearity check fails, so check for linearity first. Parameter estimation is not sensitive to the normality assumption, but prediction intervals are.
Use the Scale-Location plot, \(\sqrt{e / sd(e)} \sim \hat{y}\), to test for equal variance (aka, homoscedasticity). The square root of the absolute value of the residuals should be spread equally along a horizontal line.
The Residuals vs Leverage plot identifies influential observations. The standardized residuals should fall within the 95% probability band.
Show the code
par(mfrow =c(2, 2))plot(fit, labels.id =NULL)
These diagnostics are usually sufficient. If any of the diagnostics fail, you can re-specify the model or transform the data.
Consider the linearity assumption. The explanatory variables should each be linearly related to the response variable: \(E(\epsilon | X_j) = 0\). The Residuals vs Fitted plot tested this overall. A curved pattern in the residuals indicates a curvature in the relationship between the response and the predictor that is not explained by the model. There are other tests of linearity. The full list:
Residuals vs fits plot \((e \sim \hat{Y})\) should randomly vary around 0.
Observed vs fits plot \((Y \sim \hat{Y})\) should be symmetric along the 45-degree line.
Each \((Y \sim X_j )\) plot should have correlation \(\rho \sim 1\).
Each \((e \sim X_j)\) plot should exhibit no pattern.
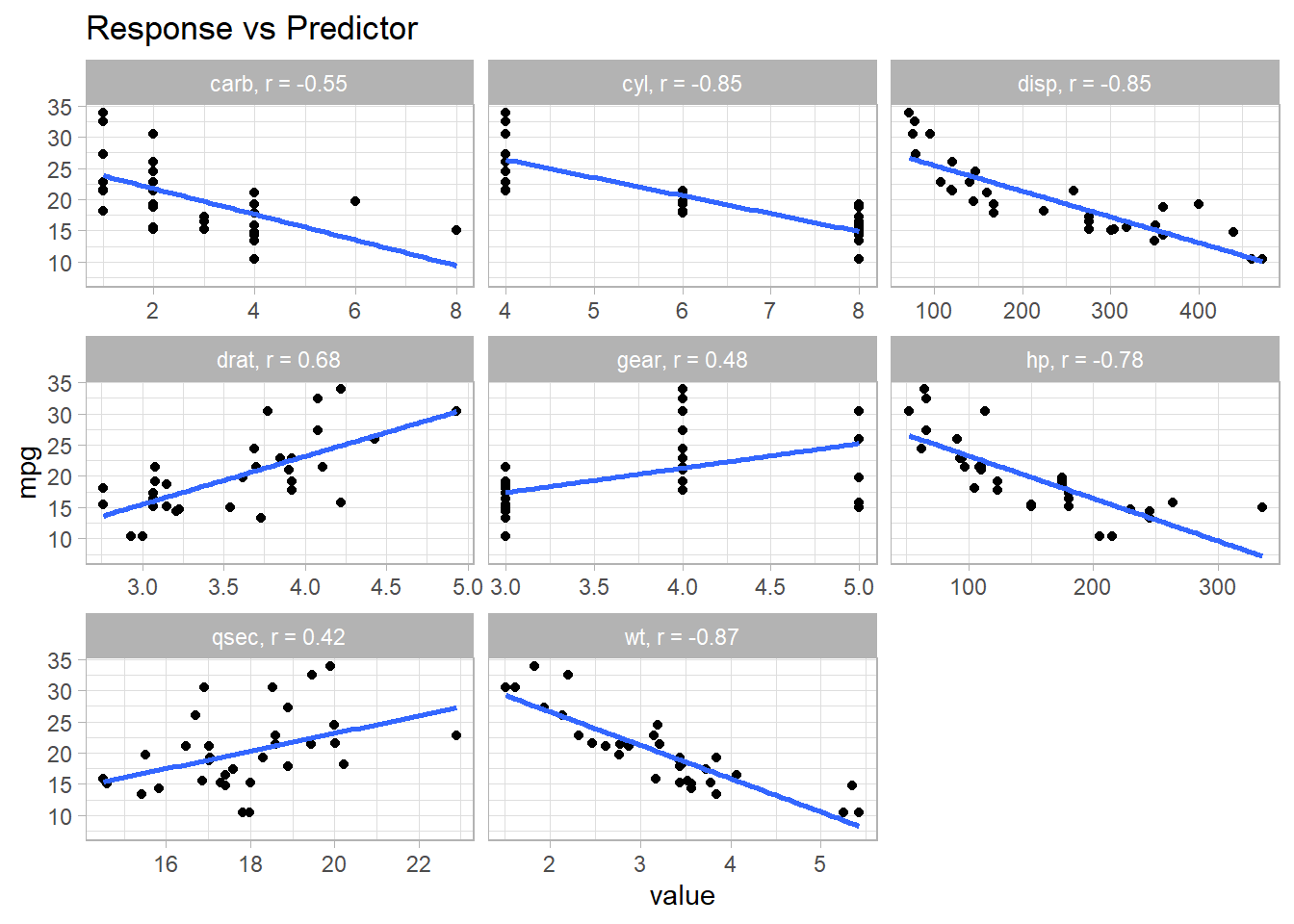
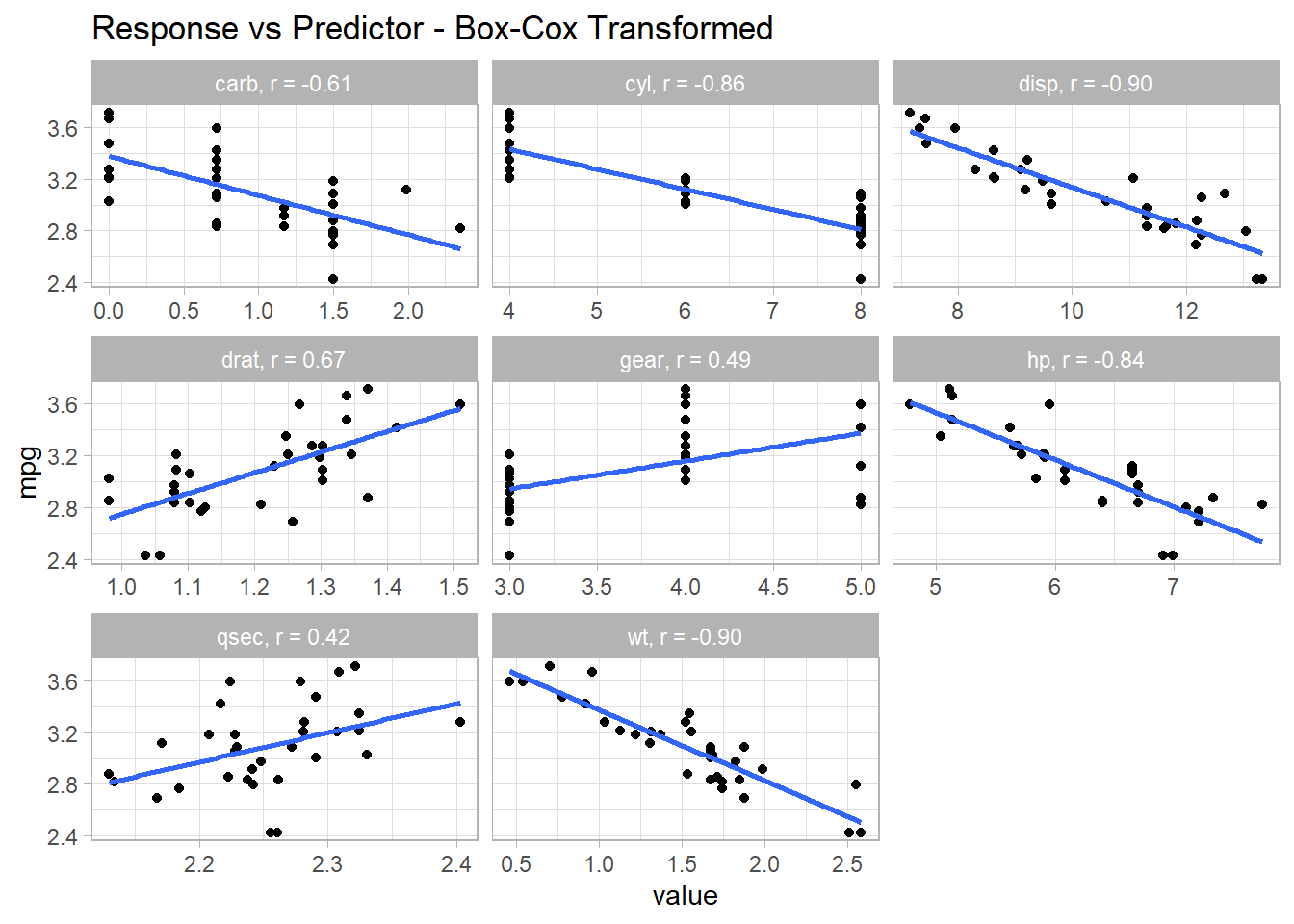
The diagnostic plots above look pretty good except for some evidence of heteroskedasticity at the upper end of predicted values. You might drill into the linearity condition to start. Start with plots of \((Y \sim X_j )\) - are the correlation coefficients ~1? Yes, all but qsec have correlations over .6.
Show the code
x <- mt_cars %>%select(where(is.numeric)) %>%pivot_longer(-mpg)x_cor <- x %>%nest(.by = name) %>%mutate(val_corr =map_dbl(data, ~cor(.$mpg, .$value)))x %>%inner_join(x_cor, by =join_by(name)) %>%mutate(name = glue::glue("{name}, r = {comma(val_corr, .01)}")) %>%ggplot(aes(x = value, y = mpg)) +geom_point() +geom_smooth(method ="lm", formula ="y ~ x", se =FALSE) +facet_wrap(facets =vars(name), scales ="free_x") +labs(title ="Response vs Predictor")
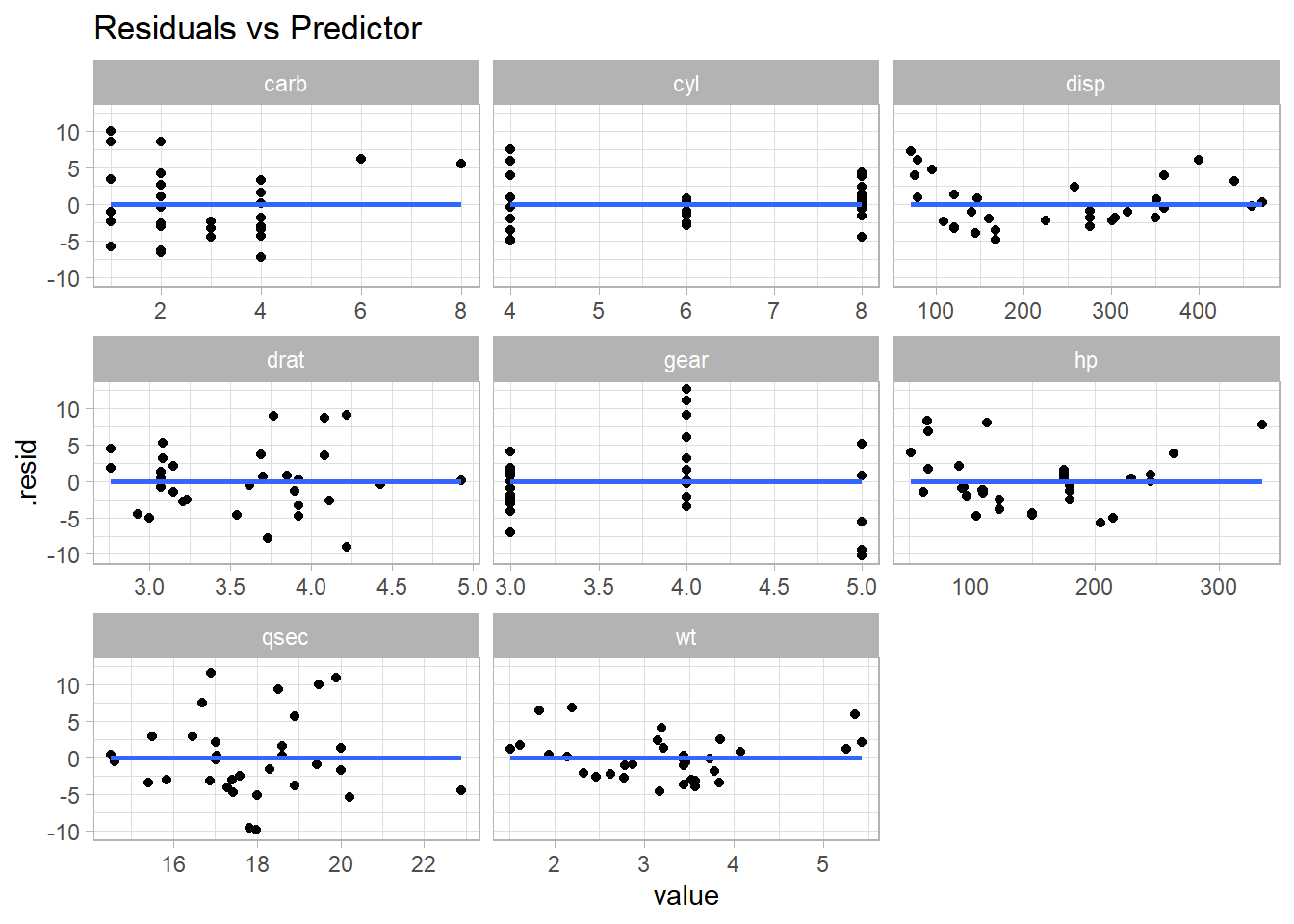
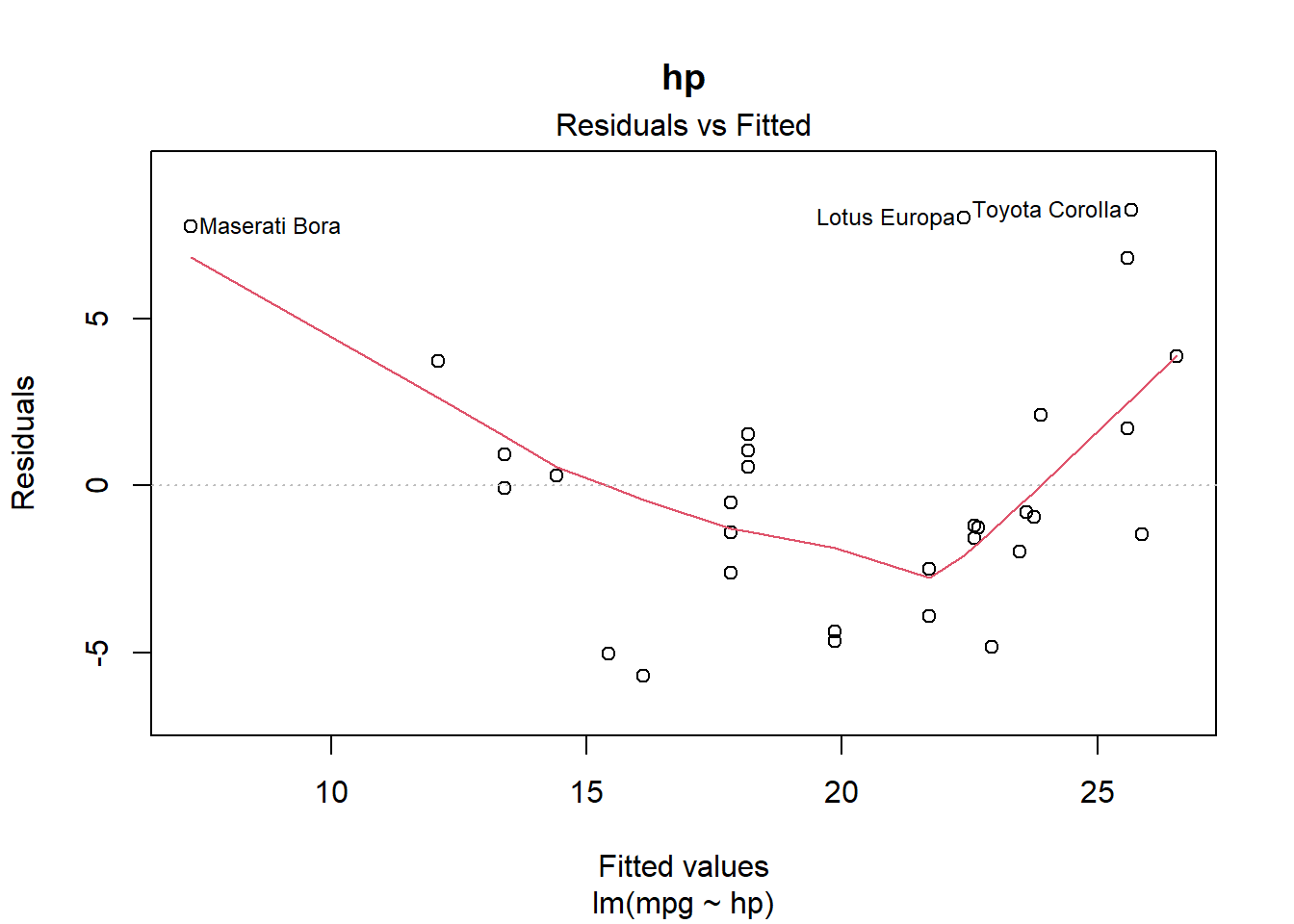
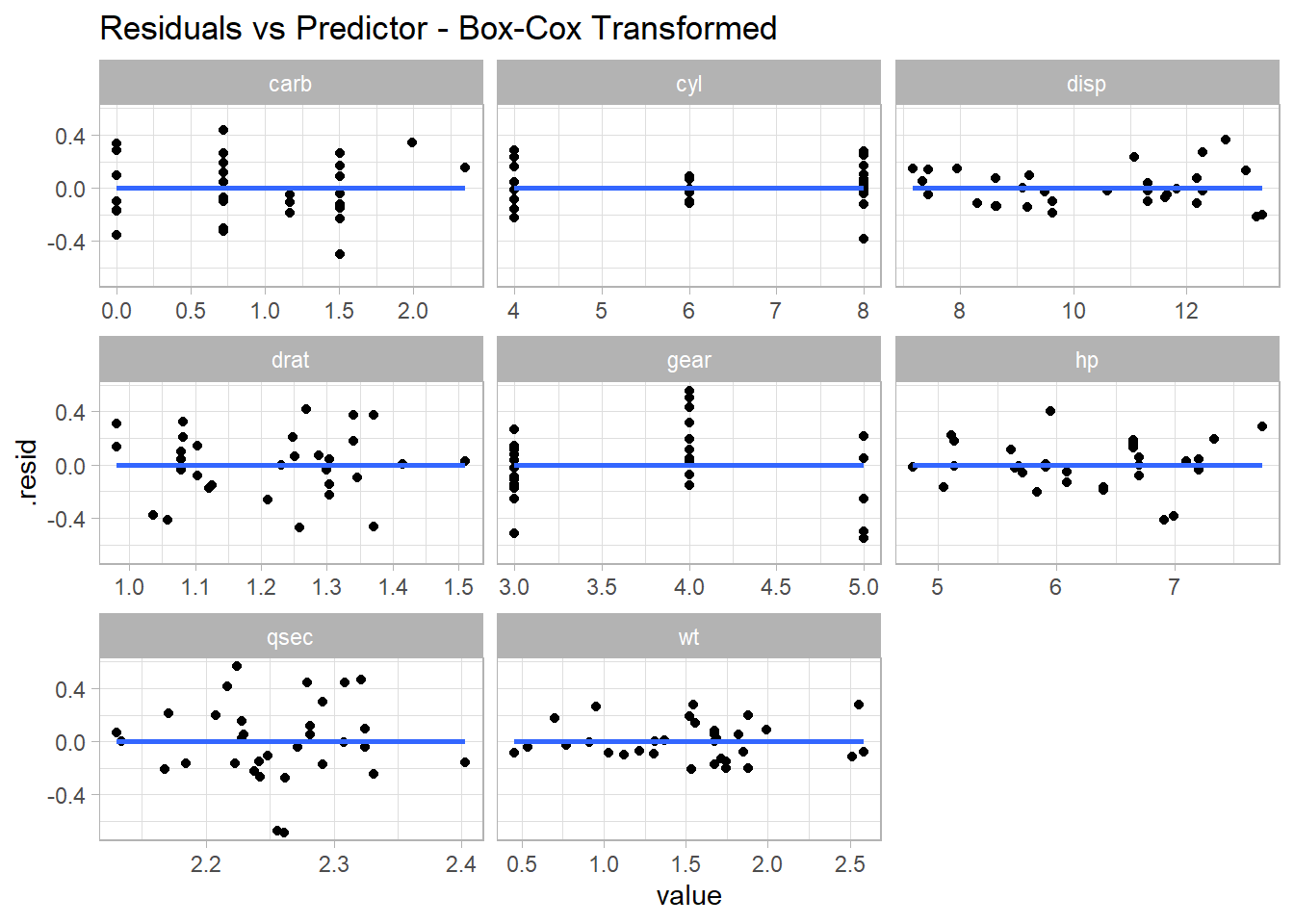
How about \((e \sim X_j)\)? disp has a wave pattern; hp is u-shaped; qsec has increase variance in the middle.
Show the code
mt_cars %>%select(where(is.numeric)) %>%pivot_longer(-mpg) %>%nest(.by = name) %>%mutate(fit =map(data, ~lm(mpg ~ value, data = .)),aug =map(fit, broom::augment) ) %>%unnest(aug) %>%ggplot(aes(x = value, y = .resid)) +geom_point() +geom_smooth(method ="lm", formula ="y ~ x", se =FALSE) +facet_wrap(facets =vars(name), scales ="free_x") +labs(title ="Residuals vs Predictor")
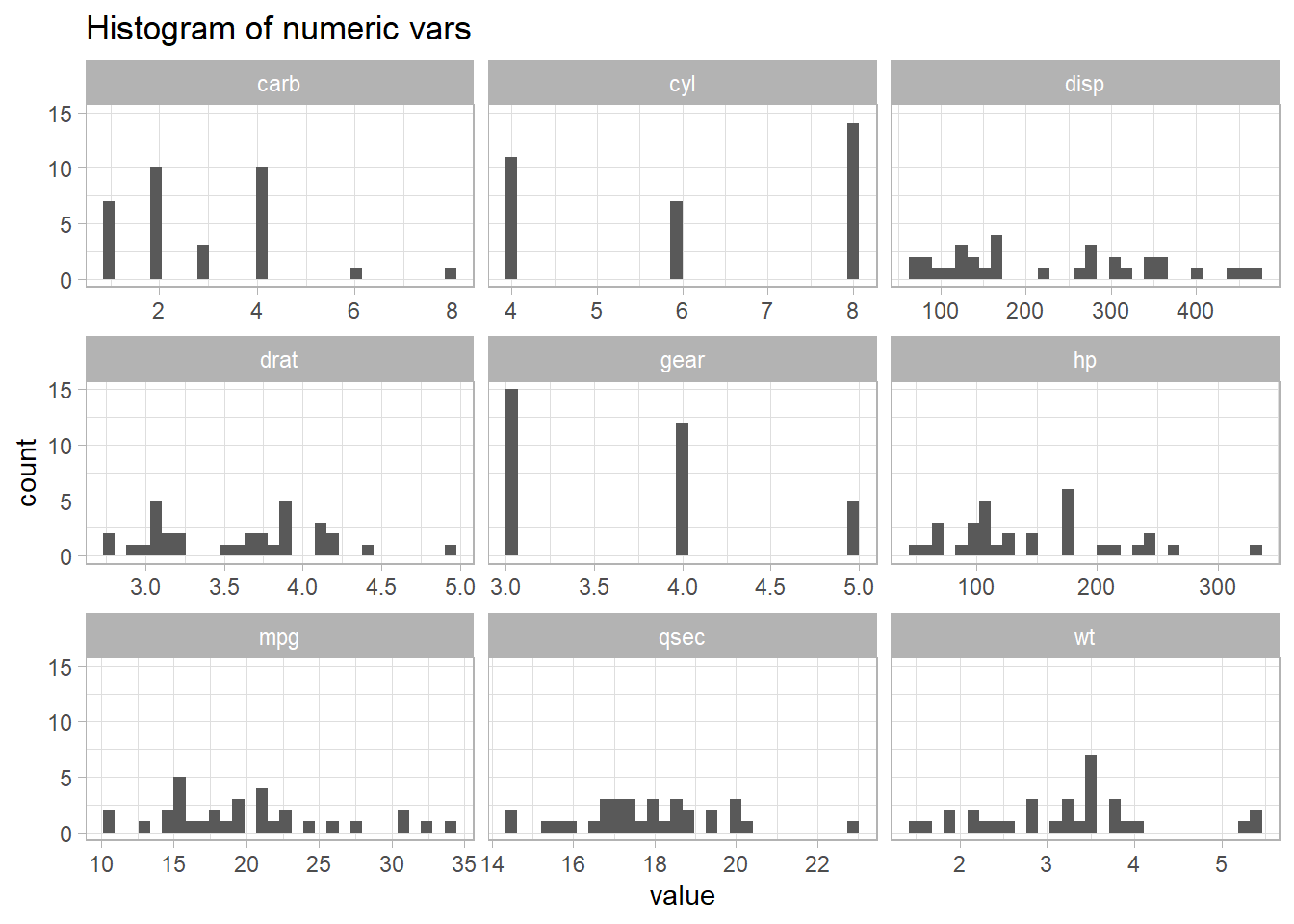
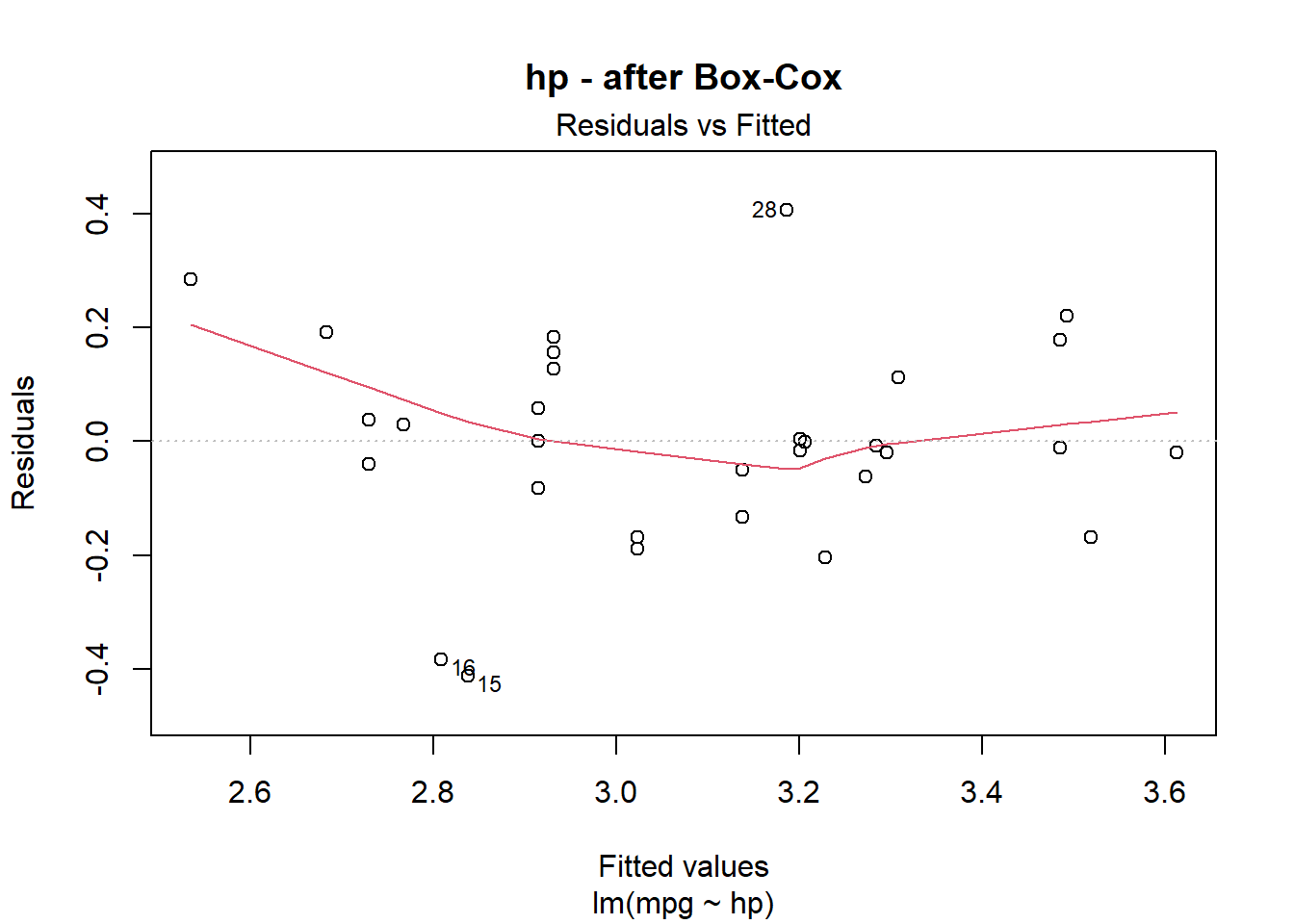
If the linearity condition fails, change the functional form of the model with non-linear transformations of the explanatory variables. A common way to do this is with Box-Cox transformations.
How about those linearity tests? Most look a little better.
Show the code
x <- mt_cars_boxcox %>%select(where(is.numeric)) %>%pivot_longer(-mpg)x_cor <- x %>%nest(.by = name) %>%mutate(val_corr =map_dbl(data, ~cor(.$mpg, .$value)))x %>%inner_join(x_cor, by =join_by(name)) %>%mutate(name = glue::glue("{name}, r = {comma(val_corr, .01)}")) %>%ggplot(aes(x = value, y = mpg)) +geom_point() +geom_smooth(method ="lm", formula ="y ~ x", se =FALSE) +facet_wrap(facets =vars(name), scales ="free_x") +labs(title ="Response vs Predictor - Box-Cox Transformed")
How about \((e \sim X_j)\)? Much better
Show the code
mt_cars_boxcox %>%select(where(is.numeric)) %>%pivot_longer(-mpg) %>%nest(.by = name) %>%mutate(fit =map(data, ~lm(mpg ~ value, data = .)),aug =map(fit, broom::augment) ) %>%unnest(aug) %>%ggplot(aes(x = value, y = .resid)) +geom_point() +geom_smooth(method ="lm", formula ="y ~ x", se =FALSE) +facet_wrap(facets =vars(name), scales ="free_x") +labs(title ="Residuals vs Predictor - Box-Cox Transformed")
1.2.1 Multicollinearity
The multicollinearity condition is violated when two or more of the predictors in a regression model are correlated. Muticollinearity can occur for structural reasons, as when one variable is a transformation of another variable, or for data reasons, as occurs in observational studies. Multicollinearity is a problem because it inflates the variances of the estimated coefficients, resulting in larger confidence intervals.
When predictor variables are correlated, the precision of their estimated regression coefficients decreases. The usual interpretation of a slope coefficient as the change in the mean response for each additional unit increase in the predictor when all the other predictors are held constant breaks down because changing one predictor necessarily changes the others.
The residuals vs fits plot \((\epsilon \sim \hat{Y})\) should have correlation \(\rho \sim 0\). A correlation matrix is helpful for picking out the correlation strengths. A good rule of thumb is correlation coefficients should be less than 0.80. However, this test may not work when a variable is correlated with a function of other variables. A model with multicollinearity may have a significant F-test with insignificant individual slope estimator t-tests. Another way to detect multicollinearity is by calculating variance inflation factors (VIF). The predictor variance \(Var(\hat{\beta_k})\) increases by a factor
\[\mathrm{VIF}_k = \frac{1}{1 - R_k^2}\]
where \(R_k^2\) is the \(R^2\) of a regression of the \(k^{th}\) predictor on the remaining predictors. A \(VIF_k\) of \(1\) indicates no inflation (no correlation). A \(VIF_k >= 4\) warrants investigation. A \(VIF_k >= 10\) requires correction.
Does the model mpg ~ . exhibit multicollinearity? Recall that the correlation matrix had several correlated predictors. E.g., disp is strongly correlated with wt (r = 0.89) and hp (r = 0.79). How about the VIFs?
Show the code
car::vif(fit_boxcox)
cyl disp hp drat wt qsec vs am
13.793609 18.078964 9.075071 3.401503 9.456176 9.117931 4.866017 4.432487
Three predictors have VIFs greater than 10 (cyl, disp, and wt). One way to address multicollinearity is removing one or more of the violating predictors from the regression model. Try removing disp.
Show the code
lm(mpg ~ . - disp, data = mt_cars_boxcox) %>% car::vif()
cyl hp drat wt qsec vs am gear
14.662069 9.587920 4.112070 8.639359 9.590966 5.034117 4.938979 5.684508
carb
5.046840
Removing disp reduced the VIFs of the other variables, but cyl is still above 10. It may be worth dropping it from the model too. The model summary shows that wt is the only significant predictor.
Show the code
lm(mpg ~ . - disp, data = mt_cars_boxcox) %>%summary()
Call:
lm(formula = mpg ~ . - disp, data = mt_cars_boxcox)
Residuals:
Min 1Q Median 3Q Max
-0.174183 -0.081250 -0.005585 0.069938 0.245160
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.57267 2.97595 0.528 0.60247
cyl 0.02864 0.04662 0.614 0.54527
hp -0.13295 0.08959 -1.484 0.15200
drat 0.13119 0.32429 0.405 0.68972
wt -0.35353 0.12046 -2.935 0.00767 **
qsec 1.00706 1.12656 0.894 0.38104
vsS -0.03579 0.09679 -0.370 0.71510
ammanual -0.01315 0.09684 -0.136 0.89324
gear 0.09776 0.07026 1.391 0.17806
carb -0.06806 0.07516 -0.906 0.37498
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1211 on 22 degrees of freedom
Multiple R-squared: 0.9015, Adjusted R-squared: 0.8612
F-statistic: 22.37 on 9 and 22 DF, p-value: 4.385e-09
1.3 Prediction
The standard error in the expected value of \(\hat{y}\) at some new set of predictors \(X_n\) is
The standard error increases the further \(X_n\) is from \(\bar{X}\). If \(X_n = \bar{X}\), the equation reduces to \(SE(\mu_\hat{y}) = \sigma / \sqrt{n}\). If \(n\) is large, or the predictor values are spread out, \(SE(\mu_\hat{y})\) will be relatively small. The \((1 - \alpha)\%\)confidence interval is \(\hat{y} \pm t_{\alpha / 2} SE(\mu_\hat{y})\).
The standard error in the predicted value of \(\hat{y}\) at some \(X_{new}\) is
Notice the standard error for a predicted value is always greater than the standard error of the expected value. The \((1 - \alpha)\%\)prediction interval is \(\hat{y} \pm t_{\alpha / 2} SE(\hat{y})\).
Calculate confidence interval and prediction interval for mpg for predictor values at their mean.
$Confidence
fit lwr upr
1 21.76575 17.75562 25.77589
$Prediction
fit lwr upr
1 21.76575 14.94985 28.58166
Verify this by calculating \(SE(\mu_\hat{y}) = \sqrt{\hat{\sigma}^2 (X_{new} (X'X)^{-1} X_{new}')}\) and \(SE(\hat{y}) = SE(\mu_\hat{y})^2 + \sqrt{\hat{\sigma}^2}\) with matrix algebra.
where \(\beta_0\) is the null-hypothesized value, usually 0. \(\sigma\) is unknown, but \(\frac{\hat{\sigma}^2 (n - k)}{\sigma^2} \sim \chi^2\). The ratio of the normal distribution divided by the adjusted chi-square \(\sqrt{\chi^2 / (n - k)}\) is t-distributed,
The \((1 - \alpha)\) confidence intervals are \(CI = \hat{\beta} \pm t_{\alpha / 2, df} SE(\hat{\beta})\) with p-value equaling the probability of measuring a \(t\) of that extreme, \(p = P(t > |t|)\). For a one-tail test, divide the reported p-value by two. The \(SE(\hat{\beta})\) decreases with i) a better fitting regression line (smaller \(\hat{\sigma}^2\)), ii) greater variation in the predictor (larger \(X'X\)), and iii) larger sample size (larger n).
The summary() output shows the t values and probabilities in the t value and Pr(>|t|) columns. Verify this using matrix algebra to solve \(t = \frac{(\hat{\beta} - \beta_1)}{SE(\hat{\beta})}\) with \(\beta_1 = 0\). The \((1 - \alpha)\) confidence interval is \(CI = \hat{\beta} \pm t_{\alpha / 2, df} SE(\hat{\beta})\).
Show the code
t <- beta_hat / se_beta_hatp_value <-pt(q =abs(t), df = n - k -1, lower.tail =FALSE) *2t_crit <-qt(p = .05/2, df = n - k -1, lower.tail =FALSE)lcl = beta_hat - t_crit * se_beta_hatucl = beta_hat + t_crit * se_beta_hatdata.frame(beta =round(beta_hat, 4), se =round(se_beta_hat, 4), t =round(t, 4), p =round(p_value, 4),lcl =round(lcl,4), ucl =round(ucl, 4)) %>% knitr::kable()
beta
se
t
p
lcl
ucl
(Intercept)
12.3034
18.7179
0.6573
0.5181
-26.6226
51.2293
cyl
-0.1114
1.0450
-0.1066
0.9161
-2.2847
2.0618
disp
0.0133
0.0179
0.7468
0.4635
-0.0238
0.0505
hp
-0.0215
0.0218
-0.9868
0.3350
-0.0668
0.0238
drat
0.7871
1.6354
0.4813
0.6353
-2.6138
4.1881
wt
-3.7153
1.8944
-1.9612
0.0633
-7.6550
0.2243
qsec
0.8210
0.7308
1.1234
0.2739
-0.6988
2.3409
vsS
0.3178
2.1045
0.1510
0.8814
-4.0588
4.6943
ammanual
2.5202
2.0567
1.2254
0.2340
-1.7568
6.7973
gear
0.6554
1.4933
0.4389
0.6652
-2.4500
3.7608
carb
-0.1994
0.8288
-0.2406
0.8122
-1.9229
1.5241
1.4.2F-Test
The F-test for the model is a test of the null hypothesis that none of the independent variables linearly predict the dependent variable, that is, the model parameters are jointly zero: \(H_0 : \beta_1 = \ldots = \beta_k = 0\). The regression mean sum of squares \(MSR = \frac{(\hat{y} - \bar{y})'(\hat{y} - \bar{y})}{k-1}\) and the error mean sum of squares \(MSE = \frac{\hat{\epsilon}'\hat{\epsilon}}{n-k}\) are each chi-square variables. Their ratio has an F distribution with \(k - 1\) numerator degrees of freedom and \(n - k\) denominator degrees of freedom. The F statistic can also be expressed in terms of the coefficient of correlation \(R^2 = \frac{MSR}{MST}\).
MSE is \(\sigma^2\). If \(H_0\) is true, that is, there is no relationship between the predictors and the response, then \(MSR\) is also equal to \(\sigma^2\), so \(F = 1\). As \(R^2 \rightarrow 1\), \(F \rightarrow \infty\), and as \(R^2 \rightarrow 0\), \(F \rightarrow 0\). F increases with \(n\) and decreases with \(k\).
What is the probability that all parameters are jointly equal to zero? The F-statistic is presented at the bottom of the summary() function. Verify this manually.
Show the code
ssr <-sum((fit$fitted.values -mean(mt_cars$mpg))^2)sse <-sum(fit$residuals^2)sst <-sum((fit$mpg -mean(mt_cars$mpg))^2)msr <- ssr / kmse <- sse / (n - k -1)f = msr / msep_value <-pf(q = f, df1 = k, df2 = n - k -1, lower.tail =FALSE)cat("F-statistic: ", round(f, 4), " on 3 and 65 DF, p-value: ", p_value)
F-statistic: 13.9325 on 3 and 65 DF, p-value: 3.793152e-07
There is sufficient evidence (F = 17.35, p < .0001) to reject \(H_0\) that the parameter estimators are jointly equal to zero.
aov() calculates the sequential sum of squares. The regression sum of squares SSR for mpg ~ cyl is 817.7. Adding disp to the model increases SSR by 37.6. Adding hp to the model increases SSR by 9.4. It would seem that hp does not improve the model.
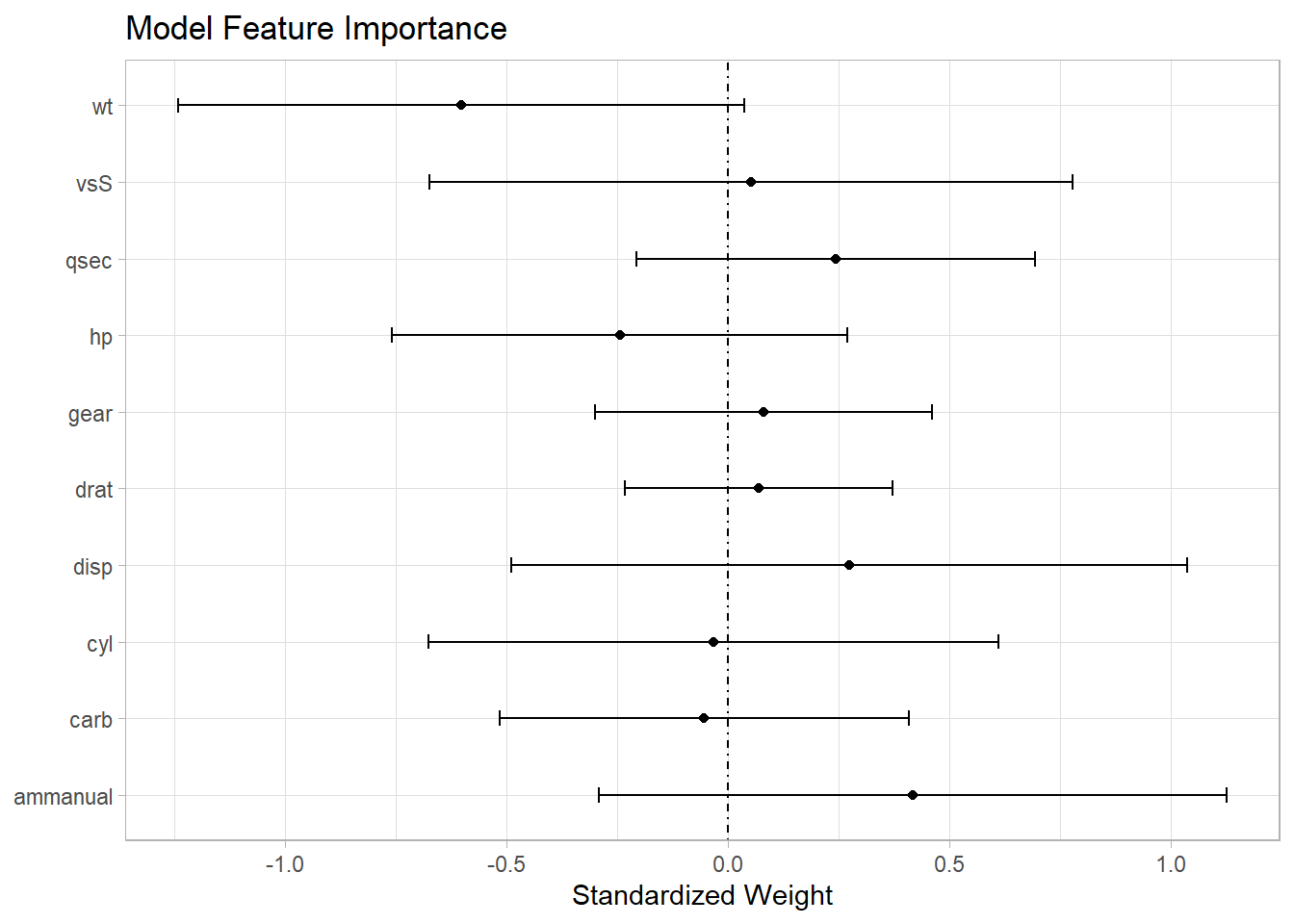
A plot of the standardized coefficients shows the relative importance of each predictor. The distance the coefficients are from zero shows how much a change in a standard deviation of the predictor changes the mean of the predicted value. The CI shows the precision. The plot shows not only which variables are significant, but also which are important.
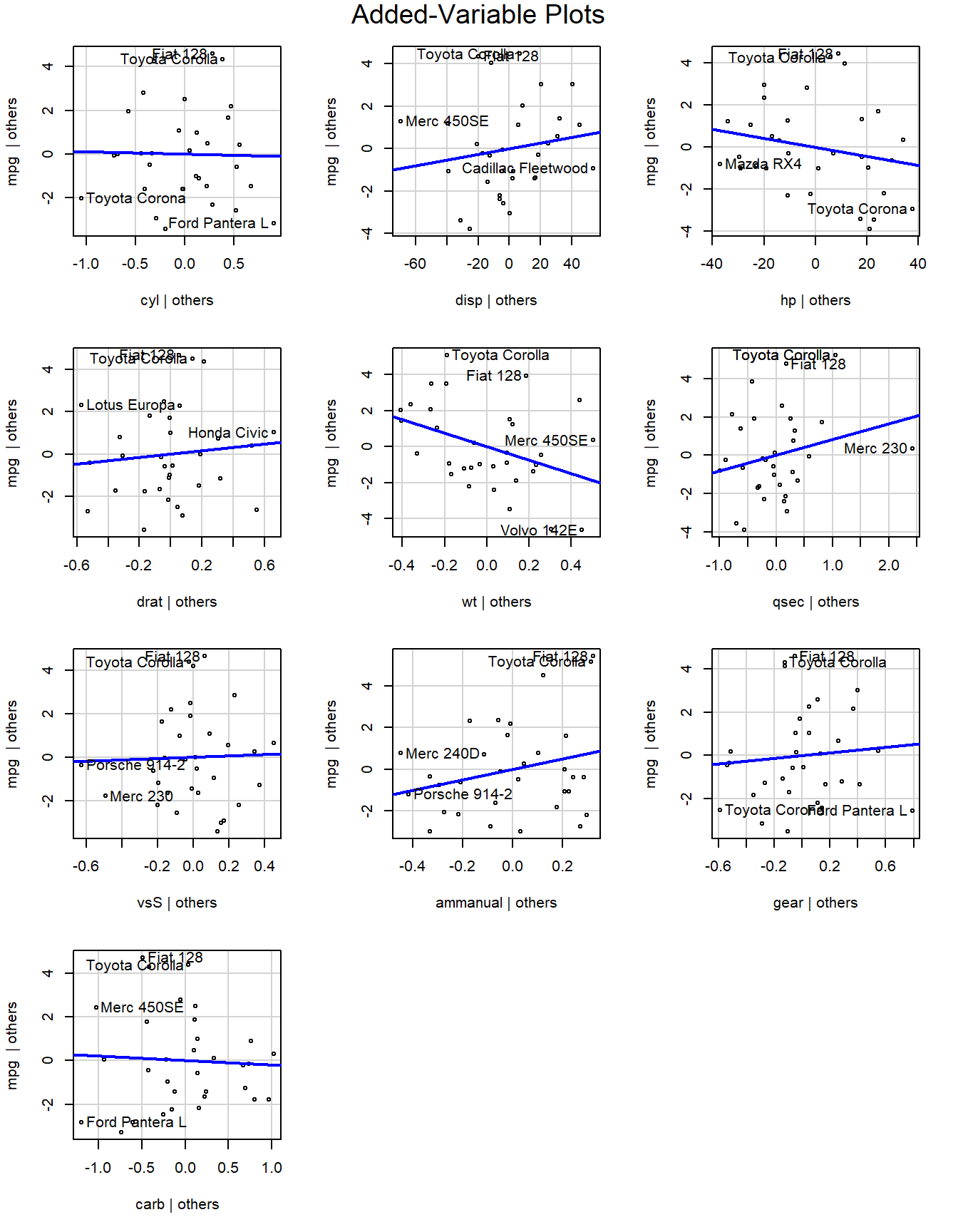
The added variable plot shows the bivariate relationship between \(Y\) and \(X_i\) after accounting for the other variables. For example, the partial regression plots of y ~ x1 + x2 + x3 would plot the residuals of y ~ x2 + x3 vs x1, and so on.
Show the code
car::avPlots(fit, layout =c(4, 3))
1.6 Model Validation
Evaluate predictive accuracy by training the model on a training data set and testing on a test data set.
1.6.1 Accuracy Metrics
The most common measures of model fit are R-squared, Adjusted R-squared, RMSE, RSE, MAE, AIC, AICc, BIC, and Mallow’s Cp.
1.6.2 R-Squared
The coefficient of determination (R-squared) is the percent of total variation in the response variable that is explained by the regression line.
\[R^2 = \frac{RSS}{SST} = 1 - \frac{SSE}{SST}\]
where \(SSE = \sum_{i=1}^n{(y_i - \hat{y}_i)^2}\) is the sum squared differences between the predicted and observed value, \(SST = \sum_{i = 1}^n{(y_i - \bar{y})^2}\) is the sum of squared differences between the observed and overall mean value, and \(RSS = \sum_{i=1}^n{(\hat{y}_i - \bar{y})^2}\) is the sum of squared differences between the predicted and overall mean “no-relationship line” value. At the extremes, \(R^2 = 1\) means all data points fall perfectly on the regression line - the predictors account for all variation in the response; \(R^2 = 0\) means the regression line is horizontal at \(\bar{y}\) - the predictors account for none of the variation in the response. In the simple case of a single predictor variable, \(R^2\) equals the squared correlation between \(x\) and \(y\), \(Cor(x,y)\).
\(R^2\) is also equal to the correlation between the fitted value and observed values, \(R^2 = Cor(Y, \hat{Y})^2\).
Show the code
cor(fit$fitted.values, mt_cars$mpg)^2
[1] 0.8690158
R-squared is proportional to the the variance in the response, SST. Given a constant percentage error in predictions, a test set with relatively low variation in the reponse will have a lower R-squared. Conversely, test sets with large variation, e.g., housing data with home sale ranging from $60K to $2M may have a large R-squared despite average prediction errors of >$10K.
A close variant of R-squared is the non-parametric Spearman’s rank correlation. This statistic is the correlation of the ranks of the response and the predicted values. It is used when the model goal is ranking.
The adjusted R-squared (\(\bar{R}^2\)) penalizes the R-squared metric for increasing number of predictors.
The mean squared error of a model with theoretical residual of mean zero and constant variance \(\sigma^2\) can be decomposed into the model’s bias and the model’s variance:
\[E[MSE] = \sigma^2 + Bias^2 + Var.\]
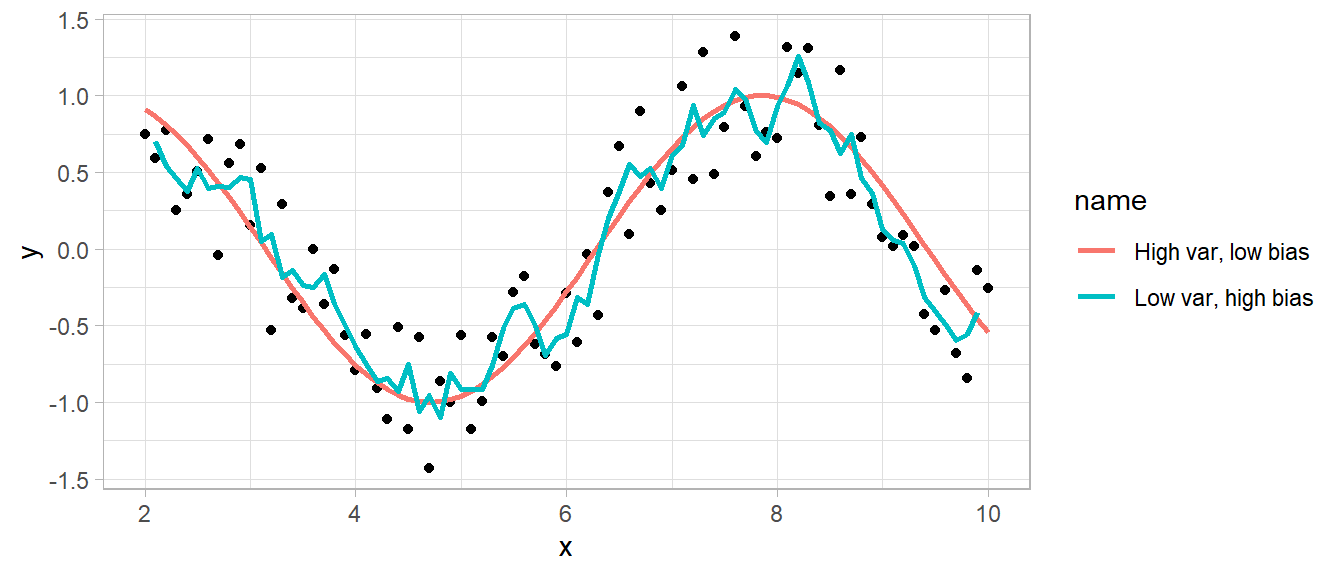
A model that predicts the response closely will have low bias, but be relatively sensitive to the training data and thus have high variance. A model that predicts the response conservatively (e.g., a simple mean) will have large bias, but be relatively insensitive to nuances in the training data. Here is an example of a simulated sine wave. A model predicting the mean value at the upper and lower levels has low variance, but high bias, and a model of an actual sine wave has low bias and high variance. This is the variance-bias trade-off.
Show the code
data.frame(x =seq(2, 10, 0.1)) %>%mutate(e =runif(81, -.5, .5),y =sin(x) + e,`Low var, high bias`= zoo:::rollmean(y, k =3, fill =NA, align ="center"),`High var, low bias`=sin(x) ) %>%pivot_longer(cols =`Low var, high bias`:`High var, low bias`) %>%ggplot(aes(x = x)) +geom_point(aes(y = y)) +geom_line(aes(y = value, color = name), size =1)
The residual standard error (RSE, or model sigma \(\hat{\sigma}\)) is an estimate of the standard deviation of \(\epsilon\). It is roughly the average amount the response deviates from the true regression line.
These metrics are good for evaluating a model, but less useful for comparing models. The problem is that they tend to improve with additional variables added to the model, even if the improvement is not significant. The following metrics aid model comparison by penalizing added variables.
1.6.2.2 AIC, BIC
Akaike’s Information Criteria (AIC) is a penalization metric. The lower the AIC, the better the model.
Show the code
AIC(fit)## [1] 163.7098# AICc corrects AIC for small sample sizes.AIC(fit) + (2* k * (k +1)) / (n - k -1)## [1] 174.186
The Bayesian information criteria (BIC) is like AIC, but with a stronger penalty for additional variables.
Show the code
BIC(fit)
[1] 181.2986
broom::glance() calculates many validation metrics. Compare the full model to a reduced model without cyl.
The adjusted R2 increased and AIC and BIC decreased, meaning the full model is less efficient at explaining the variability in the response value. The residual standard error sigma is smaller for the reduced model. Finally, the F statistic p-value is smaller for the reduced model, meaning the reduced model is statistically more significant.
Note that these regression metrics are all internal measures, that is they have been computed on the training dataset, not the test dataset.
1.6.3 Cross-Validation
Cross-validation is a set of methods for measuring the performance of a predictive model on a test dataset. The main measures of prediction performance are R2, RMSE and MAE.
1.6.3.1 Validation Set
To perform validation set cross validation, randomly split the data into a training data set and a test data set. Fit models to the training data set, then predict values with the validation set. The model that produces the best prediction performance is the preferred model.
The validation set method is only useful when you have a large data set to partition. A second disadvantage is that building a model on a fraction of the data leaves out information. The test error will vary with which observations are included in the training set.
1.6.3.2 LOOCV
Leave one out cross validation (LOOCV) works by successively modeling with training sets leaving out one data point, then averaging the prediction errors.
This method isn’t perfect either. It repeats as many times as there are data points, so the execution time may be long. LOOCV is also sensitive to outliers.
1.6.3.3 K-fold Cross-Validation
K-fold cross-validation splits the dataset into k folds (subsets), then uses k-1 of the folds for a training set and the remaining fold for a test set, then repeats for all permutations of k taken k-1 at a time. E.g., 3-fold cross-validation will partition the data into sets A, B, and C, then create train/test splits of [AB, C], [AC, B], and [BC, A].
K-fold cross-validation is less computationally expensive than LOOCV, and often yields more accurate test error rate estimates. What is the right value of k? The lower is k the more biased the estimates; the higher is k the larger the estimate variability. At the extremes k = 2 is the validation set method, and k = n is the LOOCV method. In practice, one typically performs k-fold cross-validation using k = 5 or k = 10 because these values have been empirically shown to balence bias and variance.
You can also perform k-fold cross-validation multiple times and average the results. Specify method = "repeatedcv" and repeats = 3 in the trainControl object for three repeats.
Bootstrapping randomly selects a sample of n observations with replacement from the original dataset to evaluate the model. The procedure is repeated many times.
Specify method = "boot" and number = 100 to perform 100 bootstrap samples.
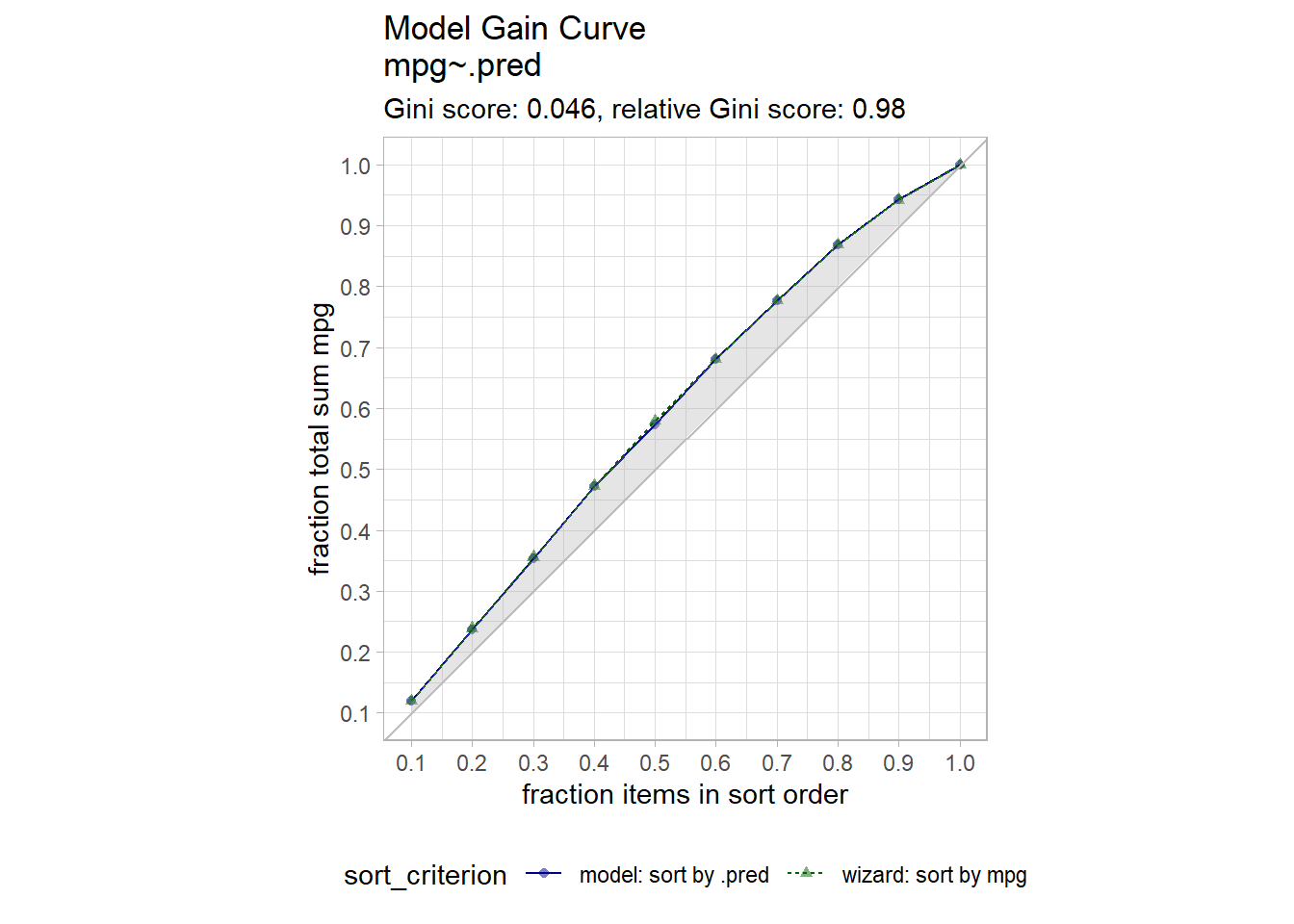
For supervised learning purposes, a visual way to evaluate a regression model is with the gain curve. This visualization compares a predictive model score to an actual outcome (either binary (0/1) or continuous). The gain curve plot measures how well the model score sorts the data compared to the true outcome value. The x-axis is the fraction of items seen when sorted by score, and the y-axis is the cumulative summed true outcome when sorted by score. For comparison, GainCurvePlot also plots the “wizard curve”: the gain curve when the data is sorted according to its true outcome. A relative Gini score close to 1 means the model sorts responses well.
Show the code
fit_validation %>% WVPlots::GainCurvePlot(xvar =".pred", truthVar ="mpg", title ="Model Gain Curve")
# Ordinary Least Squares```{r include=FALSE}library(tidyverse)library(tidymodels)```These notes rely on PSU^[Penn State University, STAT 501, Lesson 12: Multicollinearity & Other Regression Pitfalls. [https://newonlinecourses.science.psu.edu/stat501/lesson/12](https://newonlinecourses.science.psu.edu/stat501/lesson/12).], STHDA^[STHDA. Bootstrap Resampling Essentials in R. [http://www.sthda.com/english/articles/38-regression-model-validation/156-bootstrap-resampling-essentials-in-r/](http://www.sthda.com/english/articles/38-regression-model-validation/156-bootstrap-resampling-essentials-in-r/)], and [@Molner2020],The population regression model $E(Y) = X \beta$ summarizes the trend between the predictors and the mean responses. The individual responses are assumed to be normally distributed about the population regression, $y_i = X_i \beta + \epsilon_i$ with varying mean, but constant variance, $y_i \sim N(\mu_i, \sigma^2).$ Equivalently, the model presumes a linear relationship between $y$ and $X$ with residuals $\epsilon$ that are independent normal random variables with mean zero and constant variance $\sigma^2$. Estimate the population regression model coefficients as $\hat{y} = X \hat{\beta}$, and the population variance as $\hat{\sigma}^2$. The most common method of estimating the $\beta$ coefficients and $\sigma$ is ordinary least squares (OLS). OLS minimizes the sum of squared residuals from a random sample. The predicted values vary about the actual value, $e_i = y_i - \hat{y}_i$, where $\hat{y}_i = X_i \hat{\beta}$.The OLS model is the best linear unbiased estimator (BLUE) if the residuals are independent random variables normally distributed with mean zero and constant variance. Recall these conditions with the LINE pneumonic: **L**inear, **I**ndependent, **N**ormal, and **E**qual.**Linearity**. The explanatory variables are each linearly related to the response variable: $E(\epsilon | X_j) = 0$. **Independence**. The residuals are unrelated to each other. Independence is violated by repeated measurements and temporal regressors. **Normality**. The residuals are normally distributed: $\epsilon|X \sim N(0, \sigma^2I)$. **Equal Variances**. The variance of the residuals is constant (homoscedasticity): $E(\epsilon \epsilon' | X) = \sigma^2I$Additionally, there should be little **multicollinearity** among the explanatory variables.If the modeling objective is inference, fit the model with the full data set, evaluate the model fit, and interpret the parameter estimates. If the objective is prediction, fit the model with a partitioned train/test data set, cross-validate the fit with the test set, then deploy the model. Both are covered below.## Parameter EstimationThere are two model parameters to estimate: $\hat{\beta}$ estimates the coefficient vector $\beta$, and $\hat{\sigma}$ estimates the variance of the residuals along the regression line. Derive $\hat{\beta}$ by minimizing the sum of squared residuals $SSE = (y - X \hat{\beta})' (y - X \hat{\beta})$. The result is$$\hat{\beta} = (X'X)^{-1}X'y.$$The residual standard error (RSE) estimates the sample deviation around the population regression line. *(Think of each value of $X$ along the regression line as a subpopulation with mean $y_i$ and variance $\sigma^2$. This variance is assumed to be the same for all $X$.)* $$\hat{\sigma} = \sqrt{(n-k-1)^{-1} e'e}.$$The standard error for the coefficient estimators is the square root of the error variance divided by $(X'X)$.$$SE(\hat{\beta}) = \sqrt{\hat{\sigma}^2 (X'X)^{-1}}.$$Linear regression is related to correlation. The coefficient estimator for $\beta_1$ in simple linear regression is equal to the Pearson correlation coefficient multiplied by the ratio of the standard deviations of $y$ and $x$.$$\begin{align}\hat{\beta}_1 &= \frac{\sum_{i=1}^n (x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^n(x_i - \bar{x})^2} \\&= \frac{Cov(X,Y)}{Var(X)} \\&= r \cdot \frac{\sigma_Y}{\sigma_X}\end{align}$$The Pearson correlation is the ratio of the covariance of $X$ and $Y$ and product of their standard deviations.$$\begin{align}r &= \frac{\sum_{i=1}^n (x_i - \bar{x})(y_i - \bar{y})}{\sqrt{\sum_{i=1}^n(x_i - \bar{x})^2} \sqrt{\sum_{i=1}^n(y_i - \bar{y})^2}} \\&= \frac{\text{Cov}(X,Y)}{\sigma_X \sigma_Y}\end{align}$$The formula for $\hat{\beta}$ is almost identical to that of $r$ with the exception that the denominator is the variance of $X$ rather than the product of the standard deviations. The Pearson correlation is the _standardized_ linear relationship. Pearson correlation measures the strength and direction of the linear relationship between $X$ and $Y$ in a standardized form.- If $r = 0$, then $\beta_1 = 0$ and there is no linear relationship.- if $r = 1$ or $r = -1$, then the relationship is perfectly linear, and $\beta_1$ measures the relative _scale_ of $Y$ and $X$.### Example {-}Dataset `mtcars` contains response variable fuel consumption `mpg` and 10 aspects of automobile design and performance for 32 automobiles. What is the relationship between the response and its predictors?```{r message=FALSE, warning=FALSE}data("mtcars")mt_cars <- mtcars %>% mutate( vs = factor(vs, levels = c(0, 1), labels = c("V", "S")), am = factor(am, levels = c(0, 1), labels = c("automatic", "manual")) )glimpse(mt_cars)```The correlation matrix of the numeric variables shows `wt` has the strongest association with `mpg` (*r* = -0.87) followed by `disp` (*r* = -0.85) and `hp` (*r* = -0.78). `drat` is moderately correlated (*r* = 0.68), and `qsec` is weakly correlated (*r* = 0.42). Many predictors are strongly correlated with each other.```{r message=FALSE, warning=FALSE}mt_cars %>% select(where(is.numeric)) %>% cor() %>% corrplot::corrplot(type = "upper", method = "number")```Boxplots of the categorical variables reveal differences in levels.```{r}mt_cars %>%select(mpg, where(is.factor)) %>%mutate(across(where(is.factor), as.character)) %>%pivot_longer(cols =-mpg) %>%ggplot(aes(x = value, y = mpg)) +geom_boxplot() +facet_wrap(facets =vars(name), scales ="free_x")```Fit a population model to the predictors.```{r}fit <-lm(mpg ~ ., data = mt_cars)summary(fit)````summary()` shows $\hat{\beta}$ as `Estimate`, $SE({\hat{\beta}})$ as `Std. Error`, and $\hat{\sigma}$ as `Residual standard error`. You can manually perform these calculations using matrix algebra^[Help with matrix algebra in r notes at [R for Dummies](https://www.dummies.com/programming/r/how-to-do-matrix-arithmetic-in-r/)]. Recall, $\hat{\beta} = (X'X)^{-1}X'y$.```{r}X <-model.matrix(fit)y <- mt_cars$mpg(beta_hat <-solve(t(X) %*% X) %*%t(X) %*% y)```The residual standard error is $\hat{\sigma} = \sqrt{(n-k-1)^{-1} \hat{e}'\hat{e}}$.```{r collapse=TRUE}n <- nrow(X)k <- ncol(X) - 1 # exclude the intercept termy_hat <- X %*% beta_hatsse <- sum((y - y_hat)^2)(dof <- n - k - 1)(rse <- sqrt(sse / dof))```The standard errors of the coefficients are $SE(\hat{\beta}) = \sqrt{\hat{\sigma}^2 (X'X)^{-1}}$.```{r}(se_beta_hat <-sqrt(diag(rse^2*solve(t(X) %*% X))))```## Model AssumptionsThe linear regression model assumes the relationship between the predictors and the response is linear and the residuals are independent random variables normally distributed with mean zero and constant variance. Additionally, you will want to check for multicollinearity in the predictors because it can produce unreliable coefficient estimates and predicted values. The `plot()` function produces a set of diagnostic plots to test the assumptions.Use the **Residuals vs Fitted** plot, $e \sim \hat{Y}$, to test the linearity and equal error variances assumptions. The plot also identifies outliers. The polynomial trend line should show that the residuals vary around $e = 0$ in a straight horizontal line (linearity). The residuals should have random scatter in a band of constant width around 0, and no fan shape at the low and high ends (equal variances). All tests and intervals are sensitive to the equal variances condition. The plot also reveals multicollinearity. If the residuals and fitted values are correlated, multicollinearity may be a problem.Use the **Q-Q Residuals** plot (aka, residuals normal probability plot) to test the normality assumption. It plots the theoretical percentiles of the normal distribution versus the observed sample percentiles. It should be approximately linear with no bow-shaped deviations. Sometimes this normality check fails when the linearity check fails, so check for linearity first. Parameter estimation is not sensitive to the normality assumption, but prediction intervals are.Use the **Scale-Location** plot, $\sqrt{e / sd(e)} \sim \hat{y}$, to test for equal variance (aka, homoscedasticity). The square root of the absolute value of the residuals should be spread equally along a horizontal line.The **Residuals vs Leverage** plot identifies influential observations. The standardized residuals should fall within the 95% probability band.```{r warning=FALSE, message=FALSE}par(mfrow = c(2, 2))plot(fit, labels.id = NULL)```These diagnostics are usually sufficient. If any of the diagnostics fail, you can re-specify the model or transform the data.Consider the linearity assumption. The explanatory variables should _each_ be linearly related to the response variable: $E(\epsilon | X_j) = 0$. The **Residuals vs Fitted** plot tested this overall. A curved pattern in the residuals indicates a curvature in the relationship between the response and the predictor that is not explained by the model. There are other tests of linearity. The full list:* Residuals vs fits plot $(e \sim \hat{Y})$ should randomly vary around 0. * Observed vs fits plot $(Y \sim \hat{Y})$ should be symmetric along the 45-degree line. * Each $(Y \sim X_j )$ plot should have correlation $\rho \sim 1$. * Each $(e \sim X_j)$ plot should exhibit no pattern.The diagnostic plots above look pretty good except for some evidence of heteroskedasticity at the upper end of predicted values. You might drill into the linearity condition to start. Start with plots of $(Y \sim X_j )$ - are the correlation coefficients ~1? Yes, all but `qsec` have correlations over .6.```{r}x <- mt_cars %>%select(where(is.numeric)) %>%pivot_longer(-mpg)x_cor <- x %>%nest(.by = name) %>%mutate(val_corr =map_dbl(data, ~cor(.$mpg, .$value)))x %>%inner_join(x_cor, by =join_by(name)) %>%mutate(name = glue::glue("{name}, r = {comma(val_corr, .01)}")) %>%ggplot(aes(x = value, y = mpg)) +geom_point() +geom_smooth(method ="lm", formula ="y ~ x", se =FALSE) +facet_wrap(facets =vars(name), scales ="free_x") +labs(title ="Response vs Predictor")```How about $(e \sim X_j)$? `disp` has a wave pattern; `hp` is u-shaped; `qsec` has increase variance in the middle.```{r}mt_cars %>%select(where(is.numeric)) %>%pivot_longer(-mpg) %>%nest(.by = name) %>%mutate(fit =map(data, ~lm(mpg ~ value, data = .)),aug =map(fit, broom::augment) ) %>%unnest(aug) %>%ggplot(aes(x = value, y = .resid)) +geom_point() +geom_smooth(method ="lm", formula ="y ~ x", se =FALSE) +facet_wrap(facets =vars(name), scales ="free_x") +labs(title ="Residuals vs Predictor")```If the linearity condition fails, change the functional form of the model with non-linear transformations of the explanatory variables. A common way to do this is with Box-Cox transformations. $$w_t = \begin{cases} \begin{array}{l} log(y_t) \quad \quad \lambda = 0 \\(y_t^\lambda - 1) / \lambda \quad \text{otherwise} \end{array} \end{cases}$$$\lambda$ can take any value, but values near the following yield familiar transformations.* $\lambda = 1$ yields no substantive transformation. * $\lambda = 0.5$ is a square root plus linear transformation.* $\lambda = 0.333$ is a cube root plus linear transformation.* $\lambda = 0$ is a natural log transformation.* $\lambda = -1$ is an inverse transformation.A common source of non-linearity is skewed response or predictor variables (see discussion [here](https://blog.minitab.com/blog/applying-statistics-in-quality-projects/how-could-you-benefit-from-a-box-cox-transformation)). `mt_cars` has some skewed variables.```{r message=FALSE}mt_cars %>% select(where(is.numeric)) %>% pivot_longer(cols = everything()) %>% ggplot(aes(x = value)) + geom_histogram() + facet_wrap(facets = vars(name), scales = "free_x") + labs(title = "Histogram of numeric vars")````hp` has the most skew, `cyl` the least.```{r}mt_cars %>%select(where(is.numeric)) %>% moments::skewness()```Compare the residuals vs fitted plots for each variable. Here is `hp`.```{r}lm(mpg ~ hp, data = mt_cars) %>%plot(which =1, main ="hp")```and here is `cyl````{r}lm(mpg ~ cyl, data = mt_cars) %>%plot(which =1, main ="drat")```Box-Cox transform the numeric variables. The skew is reduced.```{r}rec <-recipe(~., data = mt_cars)mt_cars_boxcox <- rec %>%step_BoxCox(all_numeric()) %>%prep(training = mt_cars) %>%bake(new_data =NULL)mt_cars_boxcox %>%select(where(is.numeric)) %>% moments::skewness()```The diagnostic plot for `hp` looks much better (notice the much smaller y-axis).```{r}lm(mpg ~ hp, data = mt_cars_boxcox) %>%plot(which =1, main ="hp - after Box-Cox")```Did this create a better fitting model? A little: R^2 increased from .87 to .89.```{r collapse=TRUE}# Beforefit %>% glance()# Afterfit_boxcox <- lm(mpg ~ ., data = mt_cars_boxcox %>% select(-c(gear, carb)))fit_boxcox %>% glance()```Here's a look at the diagnostic plots for the new model.```{r}par(mfrow =c(2, 2))plot(fit_boxcox, labels.id =NULL)```How about those linearity tests? Most look a little better.```{r}x <- mt_cars_boxcox %>%select(where(is.numeric)) %>%pivot_longer(-mpg)x_cor <- x %>%nest(.by = name) %>%mutate(val_corr =map_dbl(data, ~cor(.$mpg, .$value)))x %>%inner_join(x_cor, by =join_by(name)) %>%mutate(name = glue::glue("{name}, r = {comma(val_corr, .01)}")) %>%ggplot(aes(x = value, y = mpg)) +geom_point() +geom_smooth(method ="lm", formula ="y ~ x", se =FALSE) +facet_wrap(facets =vars(name), scales ="free_x") +labs(title ="Response vs Predictor - Box-Cox Transformed")```How about $(e \sim X_j)$? Much better```{r}mt_cars_boxcox %>%select(where(is.numeric)) %>%pivot_longer(-mpg) %>%nest(.by = name) %>%mutate(fit =map(data, ~lm(mpg ~ value, data = .)),aug =map(fit, broom::augment) ) %>%unnest(aug) %>%ggplot(aes(x = value, y = .resid)) +geom_point() +geom_smooth(method ="lm", formula ="y ~ x", se =FALSE) +facet_wrap(facets =vars(name), scales ="free_x") +labs(title ="Residuals vs Predictor - Box-Cox Transformed")```### MulticollinearityThe multicollinearity condition is violated when two or more of the predictors in a regression model are correlated. Muticollinearity can occur for *structural* reasons, as when one variable is a transformation of another variable, or for *data* reasons, as occurs in observational studies. Multicollinearity is a problem because it inflates the variances of the estimated coefficients, resulting in larger confidence intervals.When predictor variables are correlated, the precision of their estimated regression coefficients decreases. The usual interpretation of a slope coefficient as the change in the mean response for each additional unit increase in the predictor when all the other predictors are held constant breaks down because changing one predictor necessarily changes the others.The residuals vs fits plot $(\epsilon \sim \hat{Y})$ should have correlation $\rho \sim 0$. A correlation matrix is helpful for picking out the correlation strengths. A good rule of thumb is correlation coefficients should be less than 0.80. However, this test may not work when a variable is correlated with a function of other variables. A model with multicollinearity may have a significant *F*-test with insignificant individual slope estimator t-tests. Another way to detect multicollinearity is by calculating variance inflation factors (VIF). The predictor variance $Var(\hat{\beta_k})$ increases by a factor $$\mathrm{VIF}_k = \frac{1}{1 - R_k^2}$$where $R_k^2$ is the $R^2$ of a regression of the $k^{th}$ predictor on the remaining predictors. A $VIF_k$ of $1$ indicates no inflation (no correlation). A $VIF_k >= 4$ warrants investigation. A $VIF_k >= 10$ requires correction.Does the model `mpg ~ .` exhibit multicollinearity? Recall that the correlation matrix had several correlated predictors. E.g., `disp` is strongly correlated with `wt` (r = 0.89) and `hp` (r = 0.79). How about the VIFs?```{r}car::vif(fit_boxcox)```Three predictors have VIFs greater than 10 (`cyl`, `disp`, and `wt`). One way to address multicollinearity is removing one or more of the violating predictors from the regression model. Try removing `disp`.```{r}lm(mpg ~ . - disp, data = mt_cars_boxcox) %>% car::vif()```Removing `disp` reduced the VIFs of the other variables, but `cyl` is still above 10. It may be worth dropping it from the model too. The model summary shows that `wt` is the only significant predictor.```{r}lm(mpg ~ . - disp, data = mt_cars_boxcox) %>%summary()```## PredictionThe standard error in the **expected value** of $\hat{y}$ at some new set of predictors $X_n$ is $$SE(\mu_\hat{y}) = \sqrt{\hat{\sigma}^2 (X_n (X'X)^{-1} X_n')}.$$ The standard error increases the further $X_n$ is from $\bar{X}$. If $X_n = \bar{X}$, the equation reduces to $SE(\mu_\hat{y}) = \sigma / \sqrt{n}$. If $n$ is large, or the predictor values are spread out, $SE(\mu_\hat{y})$ will be relatively small. The $(1 - \alpha)\%$ **confidence interval** is $\hat{y} \pm t_{\alpha / 2} SE(\mu_\hat{y})$.The standard error in the **predicted value** of $\hat{y}$ at some $X_{new}$ is $$SE(\hat{y}) = SE(\mu_\hat{y})^2 + \sqrt{\hat{\sigma}^2}.$$Notice the standard error for a predicted value is always greater than the standard error of the expected value. The $(1 - \alpha)\%$ **prediction interval** is $\hat{y} \pm t_{\alpha / 2} SE(\hat{y})$.Calculate confidence interval and prediction interval for `mpg` for predictor values at their mean.```{r message=FALSE}new_data <- mt_cars %>% summarize(across(where(is.numeric), mean)) %>% mutate(vs = "S", am = "manual")list( Confidence = predict.lm(fit, newdata = new_data, interval = "confidence"), Prediction = predict.lm(fit, newdata = new_data, interval = "prediction"))```Verify this by calculating $SE(\mu_\hat{y}) = \sqrt{\hat{\sigma}^2 (X_{new} (X'X)^{-1} X_{new}')}$ and $SE(\hat{y}) = SE(\mu_\hat{y})^2 + \sqrt{\hat{\sigma}^2}$ with matrix algebra.```{r message=FALSE, warning=FALSE}X2 <- lapply(data.frame(model.matrix(fit)), mean) %>% unlist() %>% t()X2[8] <- 1X2[9] <- 1y_exp <- sum(fit$coefficients * as.numeric(X2))# Standard error of expected and predicted valuesse_y_exp <- as.numeric(sqrt(rse^2 * X2 %*% solve(t(X) %*% X) %*% t(X2)))se_y_hat <- sqrt(rse^2 + se_y_exp^2)# Margins of errort_crit <- qt(p = .05 / 2, df = n - k - 1, lower.tail = FALSE)me_exp <- t_crit * se_y_expme_hat <- t_crit * se_y_hatlist( Confidence = c(fit = y_exp, lwr = y_exp - me_exp, upr = y_exp + me_exp), Prediction = c(fit = y_exp, lwr = y_exp - me_hat, upr = y_exp + me_hat))```## InferenceDraw conclusions about the significance of the coefficient estimates with the *t*-test and/or *F*-test.### *t*-TestBy assumption, the residuals are normally distributed, so the *Z*-test statistic could evaluate the parameter estimators, $$Z = \frac{\hat{\beta} - \beta_0}{\sqrt{\sigma^2 (X'X)^{-1}}}$$ where $\beta_0$ is the null-hypothesized value, usually 0. $\sigma$ is unknown, but $\frac{\hat{\sigma}^2 (n - k)}{\sigma^2} \sim \chi^2$. The ratio of the normal distribution divided by the adjusted chi-square $\sqrt{\chi^2 / (n - k)}$ is t-distributed, $$t = \frac{\hat{\beta} - \beta_0}{\sqrt{\hat{\sigma}^2 (X'X)^{-1}}} = \frac{\hat{\beta} - \beta_0}{SE(\hat{\beta})}$$The $(1 - \alpha)$ confidence intervals are $CI = \hat{\beta} \pm t_{\alpha / 2, df} SE(\hat{\beta})$ with *p*-value equaling the probability of measuring a $t$ of that extreme, $p = P(t > |t|)$. For a one-tail test, divide the reported p-value by two. The $SE(\hat{\beta})$ decreases with i) a better fitting regression line (smaller $\hat{\sigma}^2$), ii) greater variation in the predictor (larger $X'X$), and iii) larger sample size (larger n).The `summary()` output shows the t values and probabilities in the `t value` and `Pr(>|t|)` columns. Verify this using matrix algebra to solve $t = \frac{(\hat{\beta} - \beta_1)}{SE(\hat{\beta})}$ with $\beta_1 = 0$. The $(1 - \alpha)$ confidence interval is $CI = \hat{\beta} \pm t_{\alpha / 2, df} SE(\hat{\beta})$.```{r}t <- beta_hat / se_beta_hatp_value <-pt(q =abs(t), df = n - k -1, lower.tail =FALSE) *2t_crit <-qt(p = .05/2, df = n - k -1, lower.tail =FALSE)lcl = beta_hat - t_crit * se_beta_hatucl = beta_hat + t_crit * se_beta_hatdata.frame(beta =round(beta_hat, 4), se =round(se_beta_hat, 4), t =round(t, 4), p =round(p_value, 4),lcl =round(lcl,4), ucl =round(ucl, 4)) %>% knitr::kable()```### *F*-TestThe *F*-test for the model is a test of the null hypothesis that none of the independent variables linearly predict the dependent variable, that is, the model parameters are jointly zero: $H_0 : \beta_1 = \ldots = \beta_k = 0$. The regression mean sum of squares $MSR = \frac{(\hat{y} - \bar{y})'(\hat{y} - \bar{y})}{k-1}$ and the error mean sum of squares $MSE = \frac{\hat{\epsilon}'\hat{\epsilon}}{n-k}$ are each chi-square variables. Their ratio has an *F* distribution with $k - 1$ numerator degrees of freedom and $n - k$ denominator degrees of freedom. The F statistic can also be expressed in terms of the coefficient of correlation $R^2 = \frac{MSR}{MST}$. $$F(k - 1, n - k) = \frac{MSR}{MSE} = \frac{R^2}{1 - R^2} \frac{n-k}{k-1}$$*MSE* is $\sigma^2$. If $H_0$ is true, that is, there is no relationship between the predictors and the response, then $MSR$ is also equal to $\sigma^2$, so $F = 1$. As $R^2 \rightarrow 1$, $F \rightarrow \infty$, and as $R^2 \rightarrow 0$, $F \rightarrow 0$. *F* increases with $n$ and decreases with $k$.What is the probability that all parameters are jointly equal to zero? The *F*-statistic is presented at the bottom of the `summary()` function. Verify this manually.```{r}ssr <-sum((fit$fitted.values -mean(mt_cars$mpg))^2)sse <-sum(fit$residuals^2)sst <-sum((fit$mpg -mean(mt_cars$mpg))^2)msr <- ssr / kmse <- sse / (n - k -1)f = msr / msep_value <-pf(q = f, df1 = k, df2 = n - k -1, lower.tail =FALSE)cat("F-statistic: ", round(f, 4), " on 3 and 65 DF, p-value: ", p_value)```There is sufficient evidence (*F* = 17.35, *p* < .0001) to reject $H_0$ that the parameter estimators are jointly equal to zero.`aov()` calculates the sequential sum of squares. The regression sum of squares SSR for `mpg ~ cyl` is 817.7. Adding `disp` to the model increases SSR by 37.6. Adding `hp` to the model increases SSR by 9.4. It would seem that `hp` does not improve the model.```{r}summary(aov(fit))```Order matters. Had we started with `disp`, then added `hp` we would find both estimators were significant.```{r}summary(aov(lm(mpg ~ disp + hp + ., data = mt_cars)))```## InterpretationA plot of the standardized coefficients shows the relative importance of each predictor. The distance the coefficients are from zero shows how much a change in a standard deviation of the predictor changes the mean of the predicted value. The CI shows the precision. The plot shows not only which variables are significant, but also which are important.```{r warning=FALSE}mt_cars_scaled <- mt_cars %>% mutate(across(where(is.numeric), scale))fit_scaled <- lm(mpg ~ ., mt_cars_scaled)fit_scaled %>% tidy() %>% mutate( lwr = estimate - qt(.05/2, fit_scaled$df.residual) * std.error, upr = estimate + qt(.05/2, fit_scaled$df.residual) * std.error, ) %>% filter(term != "(Intercept)") %>% ggplot() + geom_point(aes(y = term, x = estimate)) + geom_errorbar(aes(y = term, xmin = lwr, xmax = upr), width = .2) + geom_vline(xintercept = 0, linetype = 4) + labs(title = "Model Feature Importance", x = "Standardized Weight", y = NULL) ```The added variable plot shows the bivariate relationship between $Y$ and $X_i$ after accounting for the other variables. For example, the partial regression plots of `y ~ x1 + x2 + x3` would plot the residuals of `y ~ x2 + x3` vs `x1`, and so on.```{r fig.height=9}car::avPlots(fit, layout = c(4, 3))```## Model ValidationEvaluate predictive accuracy by training the model on a training data set and testing on a test data set.### Accuracy MetricsThe most common measures of model fit are R-squared, Adjusted R-squared, RMSE, RSE, MAE, AIC, AICc, BIC, and Mallow's Cp.### R-SquaredThe coefficient of determination (**R-squared**) is the percent of total variation in the response variable that is explained by the regression line. $$R^2 = \frac{RSS}{SST} = 1 - \frac{SSE}{SST}$$where $SSE = \sum_{i=1}^n{(y_i - \hat{y}_i)^2}$ is the sum squared differences between the predicted and observed value, $SST = \sum_{i = 1}^n{(y_i - \bar{y})^2}$ is the sum of squared differences between the observed and overall mean value, and $RSS = \sum_{i=1}^n{(\hat{y}_i - \bar{y})^2}$ is the sum of squared differences between the predicted and overall mean "no-relationship line" value. At the extremes, $R^2 = 1$ means all data points fall perfectly on the regression line - the predictors account for *all* variation in the response; $R^2 = 0$ means the regression line is horizontal at $\bar{y}$ - the predictors account for *none* of the variation in the response. In the simple case of a single predictor variable, $R^2$ equals the squared correlation between $x$ and $y$, $Cor(x,y)$. ```{r collapse=TRUE}ssr <- sum((fit$fitted.values - mean(mt_cars$mpg))^2)sse <- sum(fit$residuals^2)sst <- sum((mt_cars$mpg - mean(mt_cars$mpg))^2)(r2 <- ssr / sst)(r2 <- 1 - sse / sst)(r2 <- summary(fit)$r.squared)```The sums of squares are the same thing as the variances multiplied by the degrees of freedom.```{r}ssr2 <-var(fitted(fit)) * (n -1)sse2 <-var(residuals(fit)) * (n -1)sst2 <-var(mt_cars$mpg) * (n -1)ssr2 / sst2```$R^2$ is also equal to the correlation between the fitted value and observed values, $R^2 = Cor(Y, \hat{Y})^2$.```{r}cor(fit$fitted.values, mt_cars$mpg)^2```R-squared is proportional to the the variance in the response, *SST*. Given a constant percentage error in predictions, a test set with relatively low variation in the reponse will have a lower R-squared. Conversely, test sets with large variation, e.g., housing data with home sale ranging from $60K to $2M may have a large R-squared despite average prediction errors of >$10K.A close variant of R-squared is the non-parametric Spearman's rank correlation. This statistic is the correlation of the *ranks* of the response and the predicted values. It is used when the model goal is ranking. The **adjusted R-squared** ($\bar{R}^2$) penalizes the R-squared metric for increasing number of predictors. $$\bar{R}^2 = 1 - \frac{SSE}{SST} \cdot \frac{n-1}{n-k-1}$$```{r collapse=TRUE}(adj_r2 <- 1 - sse/sst * (n - 1) / (n - k - 1))summary(fit)$adj.r.squared```#### RMSE, RSE, MAEThe root mean squared error (**RMSE**) is the average prediction error (square root of mean squared error).$$RMSE = \sqrt{\frac{\sum_{i=1}^n{(y_i - \hat{y}_i)^2}}{n}}$$```{r collapse=TRUE}sqrt(mean((mt_cars$mpg - fit$fitted.values)^2))augment(fit) %>% yardstick::rmse(truth = mpg, estimate = .fitted)```The mean squared error of a model with theoretical residual of mean zero and constant variance $\sigma^2$ can be decomposed into the model's bias and the model's variance:$$E[MSE] = \sigma^2 + Bias^2 + Var.$$A model that predicts the response closely will have low bias, but be relatively sensitive to the training data and thus have high variance. A model that predicts the response conservatively (e.g., a simple mean) will have large bias, but be relatively insensitive to nuances in the training data. Here is an example of a simulated sine wave. A model predicting the mean value at the upper and lower levels has low variance, but high bias, and a model of an actual sine wave has low bias and high variance. This is the variance-bias trade-off. ```{r warning=FALSE, fig.height=3}data.frame(x = seq(2, 10, 0.1)) %>% mutate( e = runif(81, -.5, .5), y = sin(x) + e, `Low var, high bias` = zoo:::rollmean(y, k = 3, fill = NA, align = "center"), `High var, low bias` = sin(x) ) %>% pivot_longer(cols = `Low var, high bias`:`High var, low bias`) %>% ggplot(aes(x = x)) + geom_point(aes(y = y)) + geom_line(aes(y = value, color = name), size = 1)```The residual standard error (**RSE**, or model sigma $\hat{\sigma}$) is an estimate of the standard deviation of $\epsilon$. It is roughly the average amount the response deviates from the true regression line. $$\sigma = \sqrt{\frac{\sum_{i=1}^n{(y_i - \hat{y}_i)^2}}{n-k-1}}$$```{r collapse=TRUE}sqrt(sum((mt_cars$mpg - fit$fitted.values)^2) / (n - k - 1))# sd is sqrt(sse / (n-1)), sigma = sqrt(sse / (n - k - 1))sd(fit$residuals) * sqrt((n - 1) / (n - k - 1)) summary(fit)$sigma sigma(fit)```The mean absolute error (**MAE**) is the average absolute prediction arror. It is less sensitive to outliers.$$MAE = \frac{\sum_{i=1}^n{|y_i - \hat{y}_i|}}{n}$$```{r}sum(abs(mt_cars$mpg - fit$fitted.values)) / n```These metrics are good for evaluating a model, but less useful for comparing models. The problem is that they tend to improve with additional variables added to the model, even if the improvement is not significant. The following metrics aid model comparison by penalizing added variables. #### AIC, BICAkaike's Information Criteria (**AIC**) is a penalization metric. The lower the AIC, the better the model.```{r collapse=TRUE}AIC(fit)# AICc corrects AIC for small sample sizes.AIC(fit) + (2 * k * (k + 1)) / (n - k - 1)```The Bayesian information criteria (**BIC**) is like AIC, but with a stronger penalty for additional variables.```{r}BIC(fit)````broom::glance()` calculates many validation metrics. Compare the full model to a reduced model without `cyl`.```{r}broom::glance(fit) %>%select(adj.r.squared, sigma, AIC, BIC, p.value)glance(lm(mpg ~ . - cyl, mt_cars)) %>%select(adj.r.squared, sigma, AIC, BIC, p.value)```The adjusted R2 increased and AIC and BIC decreased, meaning the full model is less efficient at explaining the variability in the response value. The residual standard error `sigma` is smaller for the reduced model. Finally, the *F* statistic p-value is smaller for the reduced model, meaning the reduced model is statistically more significant.Note that these regression metrics are all internal measures, that is they have been computed on the training dataset, not the test dataset.### Cross-ValidationCross-validation is a set of methods for measuring the performance of a predictive model on a test dataset. The main measures of prediction performance are R2, RMSE and MAE. #### Validation SetTo perform validation set cross validation, randomly split the data into a training data set and a test data set. Fit models to the training data set, then predict values with the validation set. The model that produces the best prediction performance is the preferred model.```{r collapse=TRUE}set.seed(123)mt_cars_split <- initial_split(mt_cars, prop = 0.7, strata = mpg)mt_cars_training <- mt_cars_split %>% training()mt_cars_testing <- mt_cars_split %>% testing()fit_validation <- linear_reg() %>% set_engine("lm") %>% set_mode("regression") %>% fit(mpg ~ ., data = mt_cars_training) %>% predict(new_data = mt_cars_testing) %>% bind_cols(mt_cars_testing)fit_validation %>% rmse(truth = mpg, estimate = .pred)fit_validation %>% rsq(truth = mpg, estimate = .pred)```Alternatively, `last_fit()` i) splits train/test, ii) fits, and iii) predicts.```{r eval=FALSE}fit_validation_2 <- linear_reg() %>% set_engine("lm") %>% set_mode("regression") %>% last_fit(mpg ~ ., split = mt_cars_split)fit_validation_2 %>% collect_metrics()fit_validation_2 %>% collect_predictions()```The validation set method is only useful when you have a large data set to partition. A second disadvantage is that building a model on a fraction of the data leaves out information. The test error will vary with which observations are included in the training set.#### LOOCVLeave one out cross validation (LOOCV) works by successively modeling with training sets leaving out one data point, then averaging the prediction errors.```{r eval=FALSE}set.seed(123)m2 <- train(mpg ~ ., data = d.train[, 1:9], method = "lm", trControl = trainControl(method = "LOOCV"))print(m2)postResample(pred = predict(m2, newdata = d.test), obs = d.test$mpg)```This method isn't perfect either. It repeats as many times as there are data points, so the execution time may be long. LOOCV is also sensitive to outliers.#### K-fold Cross-ValidationK-fold cross-validation splits the dataset into *k* folds (subsets), then uses *k-1* of the folds for a training set and the remaining fold for a test set, then repeats for all permutations of k taken k-1 at a time. E.g., 3-fold cross-validation will partition the data into sets A, B, and C, then create train/test splits of [AB, C], [AC, B], and [BC, A]. K-fold cross-validation is less computationally expensive than LOOCV, and often yields more accurate test error rate estimates. What is the right value of k? The lower is *k* the more biased the estimates; the higher is *k* the larger the estimate variability. At the extremes *k* = 2 is the validation set method, and *k = n* is the LOOCV method. In practice, one typically performs k-fold cross-validation using k = 5 or k = 10 because these values have been empirically shown to balence bias and variance. ```{r eval=FALSE}set.seed(123)m3 <- train(mpg ~ ., data = d.train[, 1:9], method = "lm", trControl = trainControl(method = "cv", number = 5))print(m3)postResample(pred = predict(m3, newdata = d.test), obs = d.test$mpg)```#### Repeated K-fold CVYou can also perform k-fold cross-validation multiple times and average the results. Specify `method = "repeatedcv"` and `repeats = 3` in the `trainControl` object for three repeats.```{r eval=FALSE}set.seed(123)m4 <- train(mpg ~ ., data = d.train[, 1:9], method = "lm", trControl = trainControl(method = "repeatedcv", number = 5, repeats = 3))print(m4)postResample(pred = predict(m4, newdata = d.test), obs = d.test$mpg)```#### BootstrappingBootstrapping randomly selects a sample of n observations with replacement from the original dataset to evaluate the model. The procedure is repeated many times.Specify `method = "boot"` and `number = 100` to perform 100 bootstrap samples.```{r eval=FALSE}set.seed(123)m5 <- train(mpg ~ ., data = d.train[, 1:9], method = "lm", trControl = trainControl(method = "boot", number = 100))print(m5)postResample(pred = predict(m5, newdata = d.test), obs = d.test$mpg)```### Gain CurveFor supervised learning purposes, a visual way to evaluate a regression model is with the gain curve. This visualization compares a predictive model score to an actual outcome (either binary (0/1) or continuous). The gain curve plot measures how well the model score sorts the data compared to the true outcome value. The x-axis is the fraction of items seen when sorted by score, and the y-axis is the cumulative summed true outcome when sorted by score. For comparison, GainCurvePlot also plots the "wizard curve": the gain curve when the data is sorted according to its true outcome. A relative Gini score close to 1 means the model sorts responses well.```{r message=FALSE, warning=FALSE}fit_validation %>% WVPlots::GainCurvePlot(xvar = ".pred", truthVar = "mpg", title = "Model Gain Curve")```